
Anmerkung des Herausgebers: Das Jahr 2021 geht zu Ende und wir feiern dieses Jahr mit einem 12-Tage-Weihnachts-Countdown der beliebtesten und hilfreichsten Expertenartikel im Search Engine Journal.
Diese Sammlung wurde von unserem Redaktionsteam basierend auf der Leistung, dem Nutzen, der Qualität und dem Mehrwert jedes Artikels für Sie, unsere Leser, zusammengestellt.
Bis zum 24. Dezember veröffentlichen wir jeden Tag eine der besten Kolumnen des Jahres, beginnend bei Nr. 12 und rückwärts bis Nr. 1. Heute ist Nummer 11, ursprünglich veröffentlicht am 28. Juli 2021.
Andreas Voniatis hat fantastische Arbeit geleistet und erklärt, wie man mit Python Keyword-Cluster nach Suchabsicht erstellt. Die Bilder und Screencaps machen es einfach, Schritt für Schritt mitzumachen, sodass selbst der Anfänger mit Python mitmachen kann. Gut gemacht, Andreas!
Anzeige
Weiter unten lesen
Vielen Dank, dass Sie zum Search Engine Journal beigetragen und Ihr Wissen mit den Lesern geteilt haben.
Genießen Sie alle!
Es gibt viel über die Suchabsicht zu wissen, von der Verwendung von Deep Learning zum Ableiten der Suchabsicht durch Klassifizieren von Text und Aufschlüsseln von SERP-Titeln mithilfe von Techniken der natürlichen Sprachverarbeitung (NLP) bis hin zu Clustering basierend auf semantischer Relevanz mit den erläuterten Vorteilen.
Wir kennen nicht nur die Vorteile der Entschlüsselung der Suchabsicht, sondern verfügen auch über eine Reihe von Techniken zur Skalierung und Automatisierung.
Aber oft geht es dabei um den Aufbau einer eigenen KI. Was ist, wenn Sie weder die Zeit noch das Wissen dafür haben?
Anzeige
Weiter unten lesen
In dieser Spalte erfahren Sie Schritt für Schritt, wie Sie das Keyword-Clustering nach Suchabsicht mit Python automatisieren.
SERPs enthalten Erkenntnisse zur Suchabsicht
Einige Methoden erfordern, dass Sie die gesamte Kopie aus den Titeln des Ranking-Inhalts für ein bestimmtes Keyword abrufen und diese dann in ein neuronales Netzwerkmodell einspeisen (das Sie dann erstellen und testen müssen), oder Sie verwenden NLP, um Keywords zu clustern .
Es gibt eine andere Methode, mit der Sie die eigene KI von Google verwenden können, um die Arbeit für Sie zu erledigen, ohne den gesamten Inhalt der SERPs abkratzen und ein KI-Modell erstellen zu müssen.
Nehmen wir an, Google ordnet Site-URLs nach der Wahrscheinlichkeit, dass der Inhalt die Benutzeranfrage erfüllt, in absteigender Reihenfolge. Daraus folgt, dass die SERPs wahrscheinlich ähnlich sind, wenn die Absicht für zwei Keywords gleich ist.
Viele SEO-Experten haben jahrelang die SERP-Ergebnisse für Keywords verglichen, um eine gemeinsame (oder gemeinsame) Suchabsicht abzuleiten, um über Core-Updates auf dem Laufenden zu bleiben. Dies ist also nichts Neues.
Der Mehrwert hier ist die Automatisierung und Skalierung dieses Vergleichs, die sowohl Geschwindigkeit als auch höhere Präzision bietet.
So gruppieren Sie Schlüsselwörter nach Suchabsicht in großem Maßstab mit Python (mit Code)
Beginnen Sie mit Ihren SERPs-Ergebnissen in einem CSV-Download.
Anzeige
Weiter unten lesen
1. Importieren Sie die Liste in Ihr Python-Notizbuch.
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
serps_input
Unten ist die SERPs-Datei, die jetzt in einen Pandas-Datenrahmen importiert wurde.

2. Filterdaten für Seite 1
Wir möchten die Ergebnisse der Seite 1 jeder SERP zwischen den Keywords vergleichen.
Anzeige
Weiter unten lesen
Wir teilen den Datenrahmen in Mini-Schlüsselwort-Datenrahmen auf, um die Filterfunktion auszuführen, bevor wir ihn zu einem einzelnen Datenrahmen zusammenfügen, da wir auf Schlüsselwortebene filtern möchten:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
3. Konvertieren von Ranking-URLs in einen String
Da es mehr SERP-Ergebnis-URLs als Keywords gibt, müssen wir diese URLs in eine einzige Zeile komprimieren, um die SERP des Keywords darzustellen.
Hier ist wie:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df
# Combine
strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Unten sehen Sie die SERP, die für jedes Keyword in einer einzigen Zeile komprimiert ist.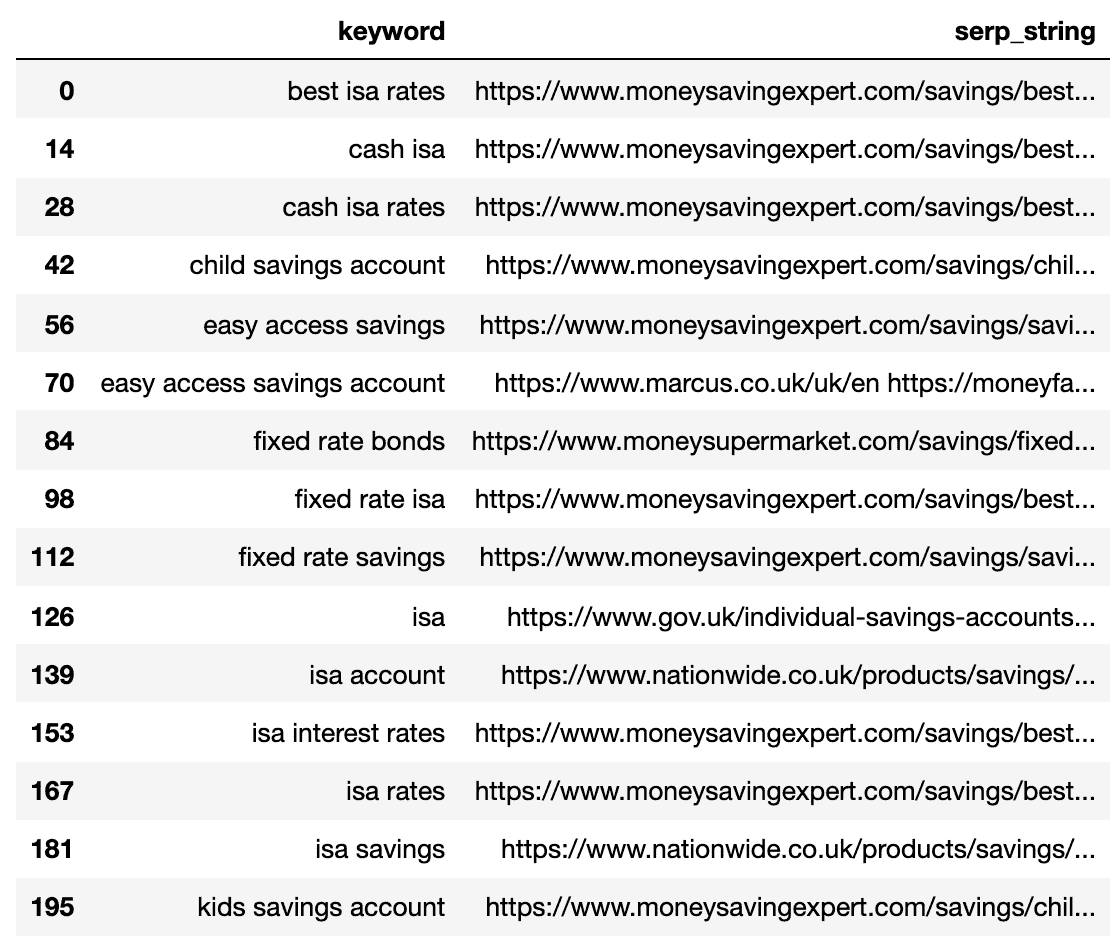
4. Vergleichen Sie die SERP-Ähnlichkeit
Um den Vergleich durchzuführen, benötigen wir nun jede Kombination von Keyword SERP gepaart mit anderen Paaren:
Anzeige
Weiter unten lesen
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = "serp_string" : "serp_string_a", 'keyword': 'keyword_a')
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = "serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword')
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps
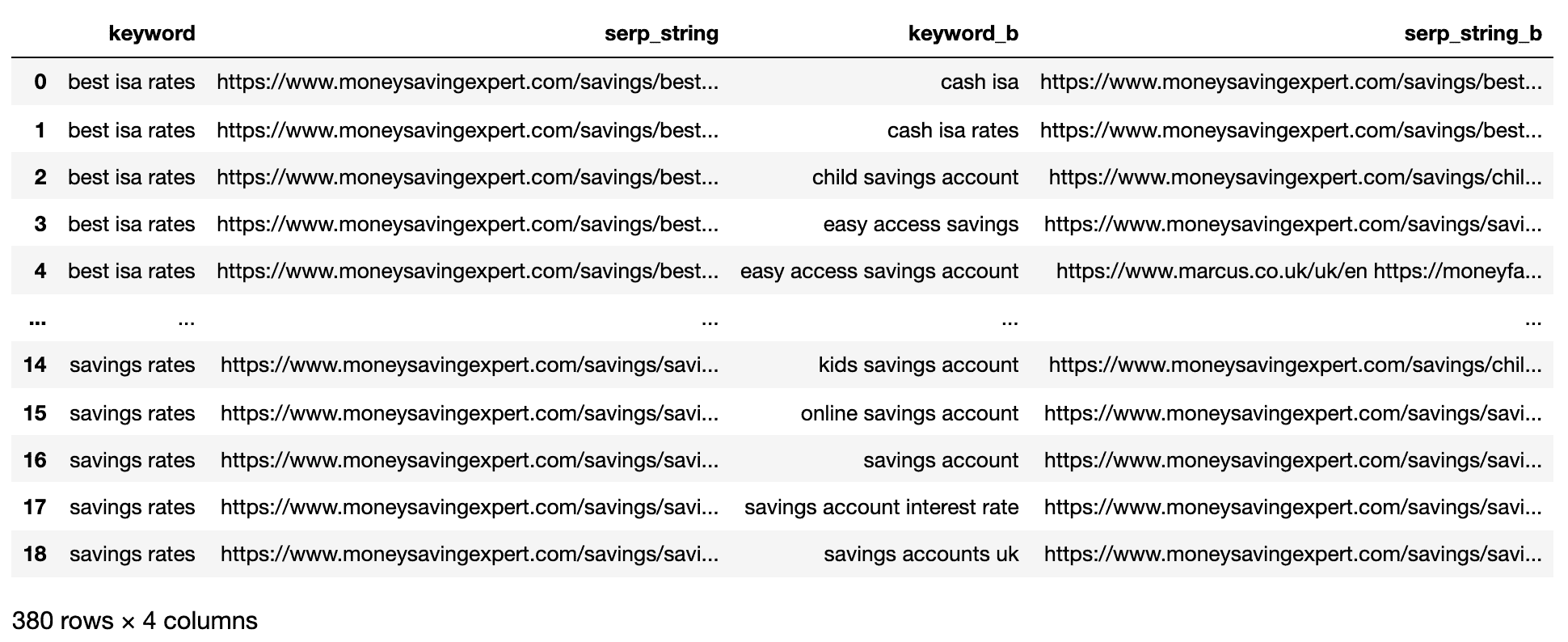
Das Obige zeigt alle Schlüsselwort-SERP-Paarkombinationen und macht es für den SERP-String-Vergleich bereit.
Es gibt keine Open-Source-Bibliothek, die Listenobjekte nach Reihenfolge vergleicht, daher wurde die Funktion unten für Sie geschrieben.
Anzeige
Weiter unten lesen
Die Funktion ‘serp_compare’ vergleicht die Überlappung von Sites und die Reihenfolge dieser Sites zwischen SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
ws_tok = sm.WhitespaceTokenizer()
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
serps_compared = matched_serps[['keyword', 'keyword_b', 'si_simi']]
serps_compared

Nachdem die Vergleiche nun ausgeführt wurden, können wir mit dem Clustering von Schlüsselwörtern beginnen.
Anzeige
Weiter unten lesen
Wir behandeln alle Keywords, die eine gewichtete Ähnlichkeit von 40% oder mehr aufweisen.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = 'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume')
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NANs
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Wir haben jetzt den potenziellen Themennamen, die SERP-Ähnlichkeit der Keywords und das Suchvolumen von jedem.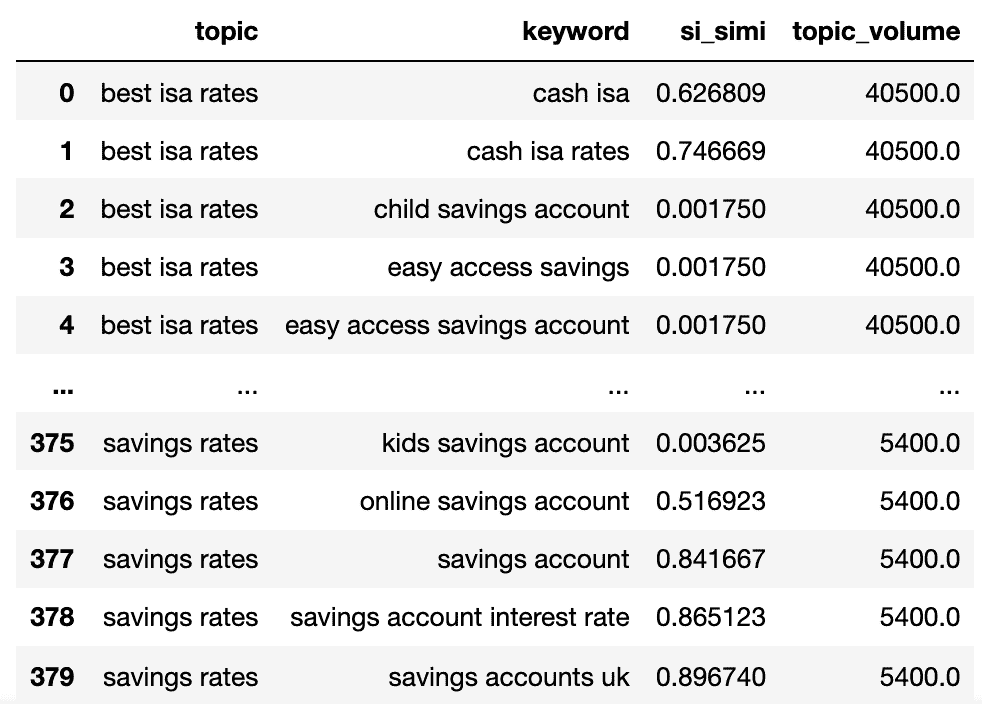
Sie werden feststellen, dass keyword und keyword_b in topic bzw. keyword umbenannt wurden.
Anzeige
Weiter unten lesen
Jetzt werden wir mit der Lamdas-Technik über die Spalten im Datenrahmen iterieren.
Die Lamdas-Technik ist eine effiziente Methode, um Zeilen in einem Pandas-Datenrahmen zu durchlaufen, da sie Zeilen im Gegensatz zur Funktion .iterrows() in eine Liste umwandelt.
Hier geht:
queries_in_df = list(set(keywords_filtered_nonnan.topic.to_list()))
topic_groups_numbered =
topics_added = []
def find_topics(si, keyw, topc):
i = 0
if (si >= simi_lim) and (not keyw in topics_added) and (not topc in topics_added):
i += 1
topics_added.append(keyw)
topics_added.append(topc)
topic_groups_numbered[i] = [keyw, topc]
elif si >= simi_lim and (keyw in topics_added) and (not topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if keyw in value]
topics_added.append(topc)
topic_groups_numbered[j[0]].append(topc)
elif si >= simi_lim and (not keyw in topics_added) and (topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if topc in value]
topics_added.append(keyw)
topic_groups_numbered[j[0]].append(keyw)
def apply_impl_ft(df):
return df.apply(
lambda row:
find_topics(row.si_simi, row.keyword, row.topic), axis=1)
apply_impl_ft(keywords_filtered_nonnan)
topic_groups_numbered = k:list(set(v)) for k, v in topic_groups_numbered.items()
topic_groups_numbered
Unten sehen Sie ein Wörterbuch mit allen Schlüsselwörtern, die nach Suchabsicht in nummerierte Gruppen gruppiert sind:
1: ['fixed rate isa', 'isa rates', 'isa interest rates', 'best isa rates', 'cash isa', 'cash isa rates'], 2: ['child savings account', 'kids savings account'], 3: ['savings account', 'savings account interest rate', 'savings rates', 'fixed rate savings', 'easy access savings', 'fixed rate bonds', 'online savings account', 'easy access savings account', 'savings accounts uk'], 4: ['isa account', 'isa', 'isa savings']
Lassen Sie uns das in einen Datenrahmen stecken:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
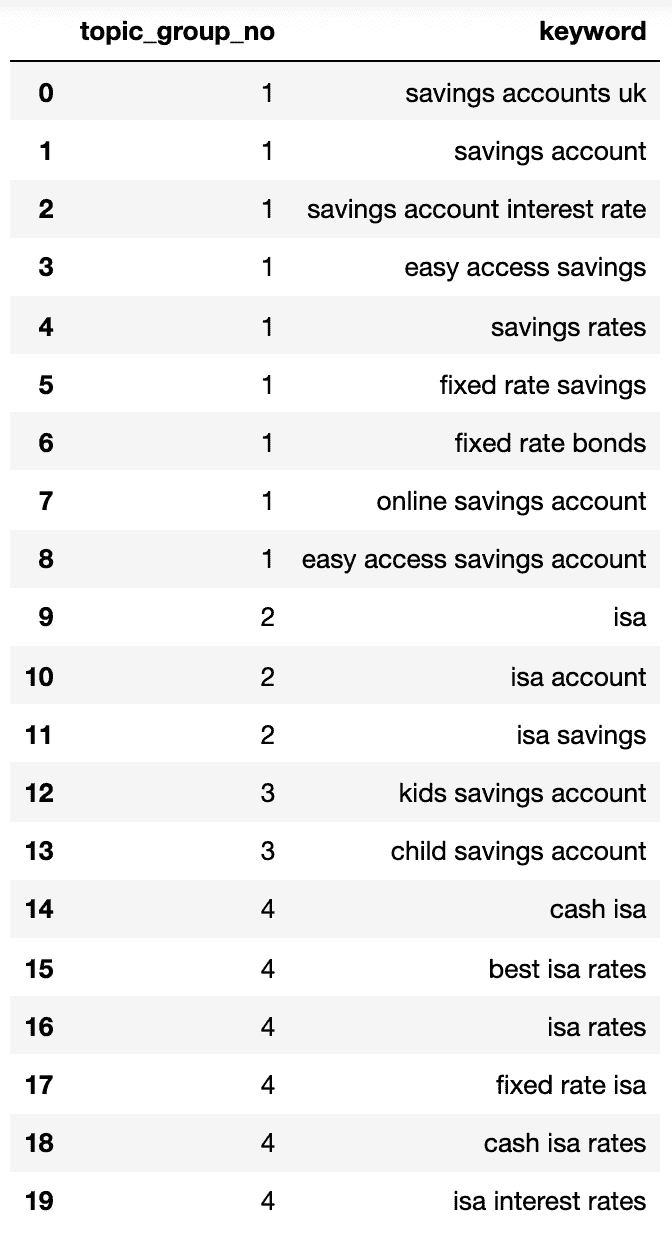
Die obigen Suchabsichtsgruppen zeigen eine gute Annäherung der darin enthaltenen Schlüsselwörter, was wahrscheinlich ein SEO-Experte erreichen würde.
Anzeige
Weiter unten lesen
Obwohl wir nur einen kleinen Satz von Schlüsselwörtern verwendet haben, kann die Methode offensichtlich auf Tausende (wenn nicht mehr) skaliert werden.
Aktivieren der Ausgänge, um Ihre Suche zu verbessern
Natürlich könnte das oben Gesagte weitergeführt werden, indem neuronale Netze verwendet werden, die den Rangfolgeinhalt für eine genauere Cluster- und Clustergruppenbenennung verarbeiten, wie es einige der kommerziellen Produkte bereits tun.
Mit dieser Ausgabe können Sie vorerst:
- Integrieren Sie dies in Ihre eigenen SEO-Dashboard-Systeme, um Ihre Trends und SEO-Berichte aussagekräftiger zu gestalten.
- Erstellen Sie besser bezahlte Suchkampagnen, indem Sie Ihre Google Ads-Konten nach Suchabsicht strukturieren, um einen höheren Qualitätsfaktor zu erzielen.
- Führen Sie redundante E-Commerce-Such-URLs mit Facetten zusammen.
- Strukturieren Sie die Taxonomie einer Shopping-Site nach der Suchabsicht anstelle eines typischen Produktkatalogs.
Anzeige
Weiter unten lesen
Ich bin sicher, es gibt noch mehr Anwendungen, die ich nicht erwähnt habe – kommentieren Sie gerne alle wichtigen Anwendungen, die ich noch nicht erwähnt habe.
Auf jeden Fall ist Ihre SEO-Keyword-Recherche jetzt noch ein bisschen skalierbarer, genauer und schneller!
2021 SEJ-Weihnachts-Countdown:
Ausgewähltes Bild: Astibuag/Shutterstock.com
Anzeige
Weiter unten lesen