
Inflection AI, die Entwickler des PI AI Personal Assistant, gaben die Entwicklung eines leistungsstarken neuen großen Sprachmodells namens Inflection-2 bekannt, das das PaLM-Sprachmodell von Google in einer Reihe von Benchmarking-Datensätzen übertrifft.
Persönlicher Pi-Assistent
Pi ist ein persönlicher Assistent, der im Internet und als App für Android- und Apple-Mobilgeräte verfügbar ist.
Es kann auch als Kontakt in WhatsApp hinzugefügt und per Facebook- und Instagram-Direktnachricht aufgerufen werden.
Pi ist als Chatbot-Assistent konzipiert, der Fragen beantworten, alles über Produkte, Wissenschaft oder Produkte recherchieren kann und als Diskussionsbegleiter fungieren kann, der Ratschläge gibt.
Das neue LLM wird bald nach der Sicherheitsprüfung in PI AI integriert.
Großes Sprachmodell Flexion-2
Inflection-2 ist ein großes Sprachmodell, das Googles PaLM 2 Large-Modell übertrifft, das derzeit das fortschrittlichste Modell von Google ist.
Inflection-2 wurde in mehreren Benchmarks getestet und mit PaLM 2 und Metas LLaMA 2 sowie anderen großen Sprachmodellen (LLMs) verglichen.
Beispielsweise kam Googles PaLM 2 beim Natural Questions-Korpus, einem Datensatz mit Fragen aus der realen Welt, kaum an Inflection-2 vorbei.
PaLM 2 erzielte einen Wert von 37,5 und Inflection-2 einen Wert von 37,3, wobei beide LLaMA 2 mit einem Wert von 33,0 übertrafen.
MMLU – Massive Multitask Language Understanding
Inflection AI hat die Benchmarking-Ergebnisse für den MMLU-Datensatz veröffentlicht, der darauf ausgelegt ist, LLMs auf ähnliche Weise wie Menschen zu testen.
Der Test umfasst 57 Fächer in den MINT-Fächern (Naturwissenschaften, Technik, Ingenieurwesen und Mathematik) und eine breite Palette anderer Fächer wie Jura.
Der Zweck des Datensatzes besteht darin, zu ermitteln, wo das LLM am stärksten und wo es am schwächsten ist.
Laut dem Forschungspapier für diesen Benchmarking-Datensatz:
„Wir schlagen einen neuen Test vor, um die Multitasking-Genauigkeit eines Textmodells zu messen.
Der Test umfasst 57 Aufgaben, darunter Grundmathematik, US-amerikanische Geschichte, Informatik, Recht und mehr.
Um bei diesem Test eine hohe Genauigkeit zu erreichen, müssen die Modelle über umfassendes Weltwissen und Problemlösungsfähigkeiten verfügen.
Wir stellen fest, dass die meisten neueren Modelle zwar eine nahezu zufällige Genauigkeit aufweisen, das allergrößte GPT-3-Modell jedoch im Durchschnitt eine Verbesserung um fast 20 Prozentpunkte gegenüber dem zufälligen Zufall aufweist.
Allerdings müssen die besten Modelle bei jeder der 57 Aufgaben noch erheblich verbessert werden, bevor sie die Genauigkeit auf Expertenniveau erreichen können.
Modelle weisen außerdem eine einseitige Leistung auf und wissen häufig nicht, wann sie falsch liegen.
Schlimmer noch, sie haben bei einigen gesellschaftlich wichtigen Themen wie Moral und Recht immer noch eine nahezu zufällige Genauigkeit.
Durch die umfassende Bewertung der Breite und Tiefe des akademischen und beruflichen Verständnisses eines Modells kann unser Test verwendet werden, um Modelle für viele Aufgaben zu analysieren und wichtige Mängel zu identifizieren.“
Dies sind die Ergebnisse des MMLU-Benchmarking-Datensatzes in der Reihenfolge vom schwächsten zum stärksten:
- LLaMA 270b 68,9
- GPT-3,5 70,0
- Grok-1 73,0
- PaLM-2 Groß 78,3
- Claude-2 _CoT 78,5
- Flexion-2 79,6
- GPT-4 86,4
Wie oben zu sehen ist, schneidet nur GPT-4 besser ab als Inflection-2.
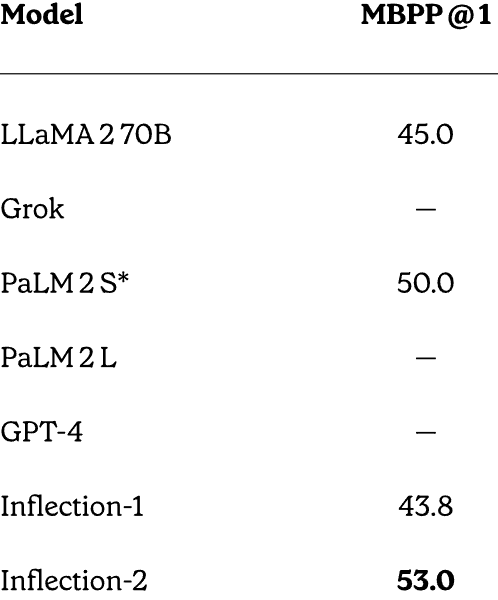
MBPP – Code- und mathematische Argumentationsleistung
Inflection AI führte einen direkten Vergleich zwischen GPT-4, PaLM 2, LLaMA und Inflection-2 bei Mathematik- und Code-Argumentationstests durch und schnitt überraschend gut ab, wenn man bedenkt, dass es nicht speziell für die Lösung mathematischer Probleme trainiert wurde.
Der verwendete Benchmarking-Datensatz heißt MBPP (Mostly Basic Python Programming). Dieser Datensatz besteht aus über 1.000 Crowdsourcing-Python-Programmierproblemen.
Was die Ergebnisse besonders bemerkenswert macht, ist, dass Inflection AI mit PaLM-2S getestet wurde, einem Variantenmodell einer großen Sprache, das speziell für die Codierung optimiert wurde.
MBPP-Ergebnisse:
- LLaMA-2 70B: 45,0
- PaLM-2S: 50,0
- Flexion-2: 53,0
Screenshot der vollständigen MBPP-Ergebnisse
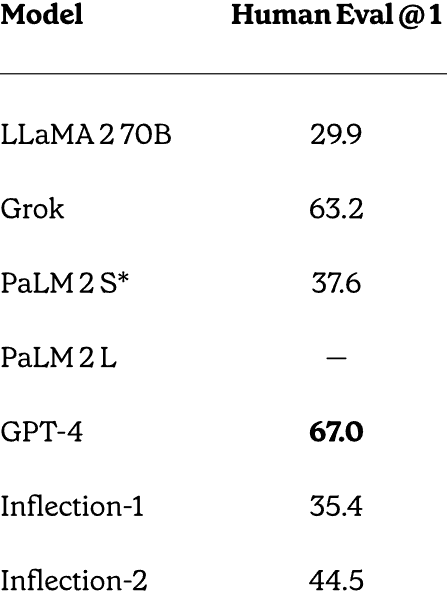
HumanEval-Datensatztest
Inflection-2 übertraf PaLM-2 auch beim Problemlösungsdatensatz HumanEval, der von OpenAI entwickelt und veröffentlicht wurde.
Hugging Face beschreibt diesen Datensatz:
„Der von OpenAI veröffentlichte HumanEval-Datensatz umfasst 164 Programmierprobleme mit einer Funktionssignatur, einem Dokumentstring, einem Hauptteil und mehreren Komponententests.
Sie wurden handgeschrieben, um sicherzustellen, dass sie nicht in den Trainingssatz der Codegenerierungsmodelle aufgenommen werden.
Die Programmieraufgaben sind in Python geschrieben und enthalten englischen Naturtext in Kommentaren und Dokumentzeichenfolgen.
Der Datensatz wurde von Ingenieuren und Forschern bei OpenAI handgefertigt.“
Das sind die Noten:
- LLaMA-2 70B: 29.9
- PaLM-2S: 37.6
- Flexion-2: 44,5
- GPT-4: 67,0
Wie oben zu sehen ist, schnitt nur GPT-4 besser ab als Inflection-2. Es sollte jedoch erneut darauf hingewiesen werden, dass Inflection-2 nicht darauf abgestimmt war, diese Art von Problemen zu lösen, was diese Ergebnisse zu einer beeindruckenden Leistung macht.
Screenshot der vollständigen HumanEval-Ergebnisse
Inflection AI erklärt, warum diese Werte wichtig sind:
„Ergebnisse zu Mathematik- und Codierungs-Benchmarks.
Während unser primäres Ziel für Inflection-2 nicht darin bestand, diese Codierungsfähigkeiten zu optimieren, sehen wir bei unserem vorab trainierten Modell eine starke Leistung bei beiden.
Es ist möglich, die Codierungsfunktionen unseres Modells durch Feinabstimmung an einem codelastigen Datensatz weiter zu verbessern.“
Ein noch leistungsfähigeres LLM kommt
In der Inflection AI-Ankündigung hieß es, dass Inflection-2 auf 5.000 NVIDIA H100-GPUs trainiert wurde. Sie planen, ein noch größeres Modell auf einem 22.000-GPU-Cluster zu trainieren, mehrere Größenordnungen größer als der 5.000-GPU-Cluster, auf dem Inflection-2 trainiert wurde.
Google und OpenAI sehen sich einer starken Konkurrenz durch geschlossene und Open-Source-Startups ausgesetzt. Inflection AI reiht sich in die Spitzengruppe der Startups mit leistungsstarker KI in der Entwicklung ein.
Der persönliche Assistent von PI ist eine Konversations-KI-Plattform mit einer zugrunde liegenden Technologie, die auf dem neuesten Stand der Technik ist und die Möglichkeit hat, noch leistungsfähiger zu werden als andere Plattformen, die für den Zugriff Gebühren erheben.
Lesen Sie die offizielle Ankündigung:
Flexion-2: Der nächste Schritt nach oben
Besuchen Sie den persönlichen Assistenten von PI online
Ausgewähltes Bild von Shutterstock/Malchevska