
Ein durchgesickertes Google-Memo bietet eine Punkt-für-Punkt-Zusammenfassung, warum Google gegen Open-Source-KI verliert, und schlägt einen Weg zurück zur Dominanz und zum Besitz der Plattform vor.
Das Memo beginnt mit der Bestätigung, dass ihr Konkurrent nie OpenAI war und immer Open Source sein würde.
Kann nicht mit Open Source konkurrieren
Darüber hinaus geben sie zu, dass sie in keiner Weise positioniert sind, um gegen Open Source anzutreten, und räumen ein, dass sie den Kampf um die KI-Dominanz bereits verloren haben.
Sie schrieben:
„Wir haben uns bei OpenAI viel über die Schulter geschaut. Wer überquert den nächsten Meilenstein? Was wird der nächste Schritt sein?
Aber die unbequeme Wahrheit ist, dass wir nicht in der Lage sind, dieses Wettrüsten zu gewinnen, und OpenAI auch nicht. Während wir uns streiten, ißt eine dritte Fraktion leise unser Mittagessen.
Ich rede natürlich von Open Source.
Einfach gesagt, sie überrunden uns. Dinge, die wir als „große offene Probleme“ betrachten, sind heute gelöst und in den Händen der Menschen.“
Der Großteil des Memos wird damit verbracht, zu beschreiben, wie Google von Open Source übertrumpft wird.
Und obwohl Google einen leichten Vorteil gegenüber Open Source hat, räumt der Autor des Memos ein, dass es sich entzieht und nie wieder zurückkehren wird.
Die Selbstanalyse der metaphorischen Karten, die sie selbst ausgeteilt haben, ist ziemlich niedergeschlagen:
„Während unsere Modelle qualitativ noch einen kleinen Vorsprung haben, schließt sich die Lücke erstaunlich schnell.
Open-Source-Modelle sind schneller, anpassbarer, privater und Pfund für Pfund leistungsfähiger.
Sie machen Dinge mit 100 $ und 13 Mrd. $ Parametern, mit denen wir bei 10 Mio. $ und 540 Mrd. $ zu kämpfen haben.
Und das in Wochen, nicht in Monaten.“
Große Sprachmodelle sind kein Vorteil
Die vielleicht erschreckendste Erkenntnis, die in dem Memo zum Ausdruck kommt, ist, dass die Größe von Google kein Vorteil mehr ist.
Die ungewöhnlich große Größe ihrer Modelle wird jetzt als Nachteil angesehen und keineswegs als unüberwindbarer Vorteil, für den sie sie hielten.
Das durchgesickerte Memo listet eine Reihe von Ereignissen auf, die darauf hindeuten, dass die Kontrolle von Google (und OpenAI) über KI schnell vorbei sein könnte.
Es wird berichtet, dass die Open-Source-Community vor kaum einem Monat, im März 2023, ein durchgesickertes Open-Source-Modell für große Sprachen erhielt, das von Meta namens LLaMA entwickelt wurde.
Innerhalb von Tagen und Wochen entwickelte die globale Open-Source-Community alle notwendigen Bauteile, um Bard- und ChatGPT-Klone zu erstellen.
Ausgeklügelte Schritte wie Instruktions-Tuning und Verstärkungslernen durch menschliches Feedback (RLHF) wurden schnell von der globalen Open-Source-Community repliziert, nicht weniger billig.
- Anleitung zum Stimmen
Ein Prozess der Feinabstimmung eines Sprachmodells, damit es etwas Bestimmtes tut, für das es ursprünglich nicht trainiert wurde. - Reinforcement Learning aus menschlichem Feedback (RLHF)
Eine Technik, bei der Menschen die Ausgabe eines Sprachmodells bewerten, damit sie lernt, welche Ausgaben für Menschen zufriedenstellend sind.
RLHF ist die Technik, die von OpenAI verwendet wird, um InstructGPT zu erstellen, ein Modell, das ChatGPT zugrunde liegt und es den Modellen GPT-3.5 und GPT-4 ermöglicht, Anweisungen entgegenzunehmen und Aufgaben zu erledigen.
RLHF ist das Feuer, das Open Source übernommen hat
Umfang von Open Source macht Google Angst
Was Google besonders Angst macht, ist die Tatsache, dass die Open-Source-Bewegung ihre Projekte so skalieren kann, wie es Closed Source nicht kann.
Der Frage-und-Antwort-Datensatz, der zum Erstellen des Open-Source-ChatGPT-Klons Dolly 2.0 verwendet wurde, wurde vollständig von Tausenden von freiwilligen Mitarbeitern erstellt.
Google und OpenAI stützten sich teilweise auf Fragen und Antworten von Seiten wie Reddit.
Der von Databricks erstellte Open-Source-Frage-und-Antwort-Datensatz soll von höherer Qualität sein, da die Menschen, die zu seiner Erstellung beigetragen haben, Fachleute waren und die Antworten, die sie gegeben haben, länger und aussagekräftiger waren als das, was in einem typischen Frage-und-Antwort-Datensatz zu finden ist, der aus einem abgekratzt wurde öffentliches Forum.
Das durchgesickerte Memo bemerkte:
„Anfang März bekam die Open-Source-Community ihr erstes wirklich leistungsfähiges Basismodell in die Hände, als Metas LLaMA der Öffentlichkeit zugespielt wurde.
Es hatte keine Anweisung oder Konversationsabstimmung und kein RLHF.
Nichtsdestotrotz verstand die Gemeinde sofort die Bedeutung dessen, was ihnen gegeben worden war.
Es folgte eine gewaltige Flut von Innovationen, mit nur wenigen Tagen zwischen den großen Entwicklungen …
Hier sind wir, kaum einen Monat später, und es gibt Varianten mit Anweisungsabstimmung, Quantisierung, Qualitätsverbesserungen, menschlicher Bewertung, Multimodalität, RLHF usw. usw., von denen viele aufeinander aufbauen.
Am wichtigsten ist, dass sie das Skalierungsproblem so weit gelöst haben, dass jeder basteln kann.
Viele der neuen Ideen stammen von gewöhnlichen Menschen.
Die Eintrittsbarriere für Training und Experimente ist von der Gesamtleistung einer großen Forschungsorganisation auf eine Person, einen Abend und einen kräftigen Laptop gesunken.“
Mit anderen Worten, was Google und OpenAI Monate und Jahre gekostet haben, um es zu trainieren und aufzubauen, dauerte für die Open-Source-Community nur wenige Tage.
Das muss für Google ein wirklich beängstigendes Szenario sein.
Dies ist einer der Gründe, warum ich so viel über die Open-Source-KI-Bewegung geschrieben habe, da es wirklich so aussieht, als würde die Zukunft der generativen KI in relativ kurzer Zeit liegen.
Open Source hat Closed Source historisch überholt
Das Memo zitiert die jüngsten Erfahrungen mit DALL-E von OpenAI, dem Deep-Learning-Modell, das zur Erstellung von Bildern verwendet wird, im Vergleich zu Open Source Stable Diffusion als Vorbote dessen, was derzeit generative KI wie Bard und ChatGPT betrifft.
Dall-e wurde im Januar 2021 von OpenAI veröffentlicht. Stable Diffusion, die Open-Source-Version, wurde anderthalb Jahre später im August 2022 veröffentlicht und überholte in wenigen Wochen die Popularität von Dall-E.
Dieses Zeitdiagramm zeigt, wie schnell Stable Diffusion Dall-E überholte:
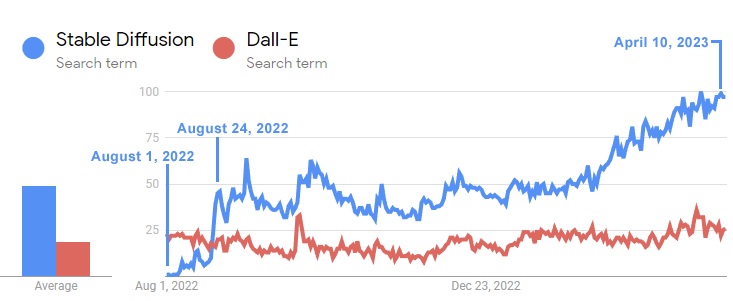
Die obige Zeitleiste von Google Trends zeigt, wie das Interesse an dem Open-Source-Stable-Diffusion-Modell innerhalb von drei Wochen nach seiner Veröffentlichung das von Dall-E bei weitem übertraf.
Und obwohl Dall-E seit anderthalb Jahren auf dem Markt war, stieg das Interesse an Stable Diffusion weiterhin exponentiell, während Dall-E von OpenAI stagnierte.
Die existenzielle Bedrohung durch ähnliche Ereignisse, die Bard (und OpenAI) überholen, bereitet Google Albträume.
Der Erstellungsprozess des Open-Source-Modells ist überlegen
Ein weiterer Faktor, der die Ingenieure bei Google alarmiert, ist, dass der Prozess zur Erstellung und Verbesserung von Open-Source-Modellen schnell und kostengünstig ist und sich perfekt für einen globalen kooperativen Ansatz eignet, der für Open-Source-Projekte üblich ist.
Das Memo stellt fest, dass neue Techniken wie LoRA (Low-Rank Adaptation of Large Language Models) die Feinabstimmung von Sprachmodellen innerhalb weniger Tage mit äußerst geringen Kosten ermöglichen, wobei das endgültige LLM mit den äußerst teureren LLMs vergleichbar ist erstellt von Google und OpenAI.
Ein weiterer Vorteil besteht darin, dass Open-Source-Ingenieure auf früheren Arbeiten aufbauen und iterieren können, anstatt bei Null anfangen zu müssen.
Das Erstellen großer Sprachmodelle mit Milliarden von Parametern, wie es OpenAI und Google getan haben, ist heute nicht mehr notwendig.
Dies könnte der Punkt sein, auf den Sam Alton kürzlich anspielte, als er kürzlich sagte, dass die Ära der massiven großen Sprachmodelle vorbei ist.
Der Autor des Google-Memos stellte den billigen und schnellen LoRA-Ansatz zur Erstellung von LLMs dem aktuellen großen KI-Ansatz gegenüber.
Der Memo-Autor reflektiert das Manko von Google:
„Im Gegensatz dazu wirft das Training riesiger Modelle von Grund auf nicht nur das Vortraining weg, sondern auch alle iterativen Verbesserungen, die darüber gemacht wurden. In der Open-Source-Welt dauert es nicht lange, bis diese Verbesserungen dominieren, was eine vollständige Umschulung extrem kostspielig macht.
Wir sollten darüber nachdenken, ob jede neue Anwendung oder Idee wirklich ein ganz neues Modell braucht.
… In der Tat übertrifft das Verbesserungstempo dieser Modelle in Bezug auf die Ingenieurstunden bei weitem das, was wir mit unseren größten Varianten erreichen können, und die besten sind bereits weitgehend nicht von ChatGPT zu unterscheiden.“
Der Autor schließt mit der Erkenntnis, dass das, was sie für ihren Vorteil hielten, ihre riesigen Modelle und die damit verbundenen unerschwinglichen Kosten, tatsächlich ein Nachteil waren.
Der global-kollaborative Charakter von Open Source ist effizienter und um Größenordnungen schneller bei der Innovation.
Wie kann ein Closed-Source-System gegen die überwältigende Vielzahl von Ingenieuren auf der ganzen Welt antreten?
Der Autor kommt zu dem Schluss, dass sie nicht konkurrieren können und dass der direkte Wettbewerb in ihren Worten ein „verlierendes Angebot“ ist.
Das ist die Krise, der Sturm, der sich außerhalb von Google entwickelt.
Wenn Sie Open Source nicht schlagen können, schließen Sie sich ihnen an
Der einzige Trost, den der Memo-Autor in Open Source findet, ist, dass, weil die Open-Source-Innovationen kostenlos sind, auch Google davon profitieren kann.
Abschließend kommt der Autor zu dem Schluss, dass der einzige Ansatz, der Google offen steht, darin besteht, die Plattform in der gleichen Weise zu besitzen, wie sie die Open-Source-Plattformen Chrome und Android dominieren.
Sie weisen darauf hin, wie Meta von der Veröffentlichung ihres großen LLaMA-Sprachmodells für die Forschung profitiert und wie sie jetzt Tausende von Menschen haben, die ihre Arbeit kostenlos erledigen.
Vielleicht ist die große Erkenntnis aus dem Memo, dass Google in naher Zukunft versuchen könnte, seine Open-Source-Dominanz zu replizieren, indem es seine Projekte auf Open-Source-Basis veröffentlicht und dadurch die Plattform besitzt.
Das Memo kommt zu dem Schluss, dass der Übergang zu Open Source die praktikabelste Option ist:
„Google sollte sich als führendes Unternehmen in der Open-Source-Community etablieren und die Führung übernehmen, indem es mit der breiteren Diskussion kooperiert, anstatt sie zu ignorieren.
Dies bedeutet wahrscheinlich, dass einige unangenehme Schritte unternommen werden, wie z. B. die Veröffentlichung der Modellgewichte für kleine ULM-Varianten. Das bedeutet zwangsläufig, dass wir die Kontrolle über unsere Modelle aufgeben.
Aber dieser Kompromiss ist unvermeidlich.
Wir können nicht darauf hoffen, Innovationen sowohl voranzutreiben als auch zu kontrollieren.“
Open Source verabschiedet sich mit dem KI-Feuer
Letzte Woche habe ich eine Anspielung auf den griechischen Mythos des menschlichen Helden Prometheus gemacht, der den Göttern auf dem Olymp das Feuer stiehlt, und die Open Source zu Prometheus gegen die „olympischen Götter“ von Google und OpenAI ausgespielt:
ICH getwittert:
„Während Google, Microsoft und Open AI miteinander streiten und sich den Rücken zukehren, geht Open Source mit ihrem Feuer davon?“
Das Leck von Googles Memo bestätigt diese Beobachtung, weist aber auch auf einen möglichen Strategiewechsel bei Google hin, sich der Open-Source-Bewegung anzuschließen und sie dadurch zu kooptieren und zu dominieren, so wie sie es mit Chrome und Android getan haben.
Lesen Sie hier das durchgesickerte Google-Memo:
Google „Wir haben keinen Wassergraben und OpenAI auch nicht“