Die robots.txt-Datei des persönlichen Blogs von John Mueller von Google geriet in den Mittelpunkt des Interesses, als jemand auf Reddit behauptete, Muellers Blog sei vom System „Hilfreiche Inhalte“ betroffen und daraufhin deindexiert worden. Die Wahrheit erwies sich als weniger dramatisch, war aber dennoch ein wenig seltsam.
SEO-Subreddit-Beitrag
Die Saga von John Muellers robots.txt begann, als ein Redditor veröffentlichte, dass die Website von John Mueller deindexiert wurde und dass sie mit dem Algorithmus von Google in Konflikt geraten sei. Aber so ironisch das auch sein mag, das würde nie der Fall sein, denn es dauerte nur ein paar Sekunden, um die robots.txt-Datei der Website abzurufen und zu erkennen, dass etwas Seltsames vor sich ging.
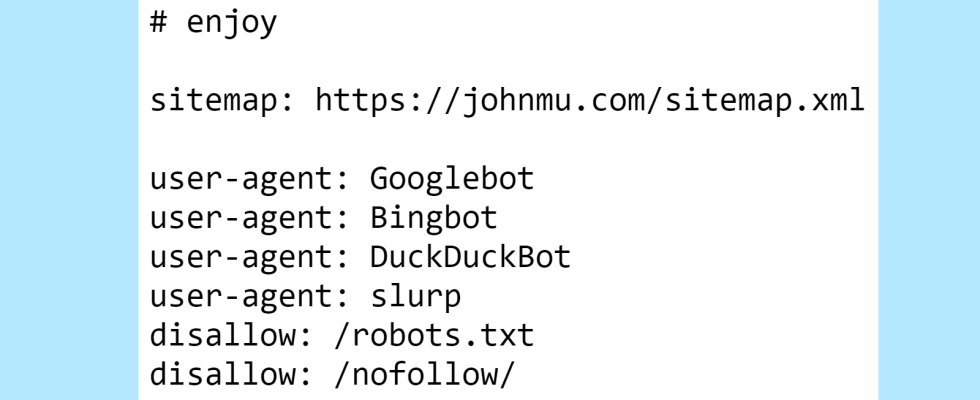
Hier ist der obere Teil von Muellers robots.txt, der ein kommentiertes Easter Egg für diejenigen enthält, die einen Blick darauf werfen.
Der erste Teil, der nicht jeden Tag zu sehen ist, ist ein Disallow in der robots.txt. Wer weist Google mithilfe seiner robots.txt-Datei an, seine robots.txt-Datei nicht zu crawlen?
Jetzt wissen wir.
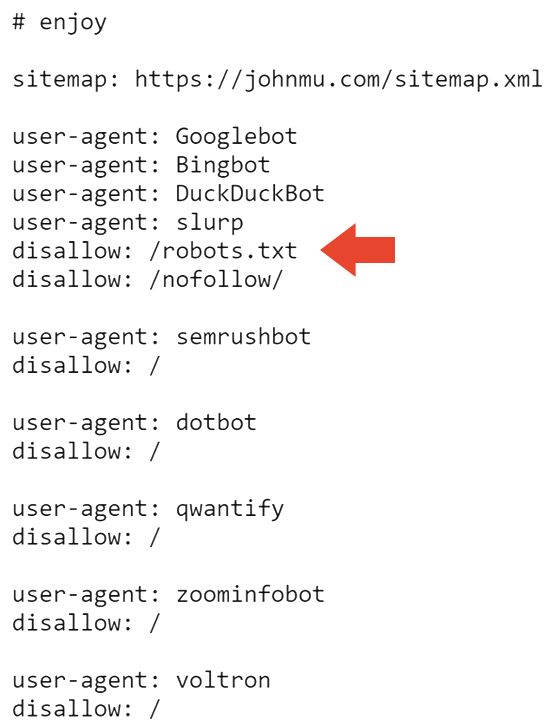
Der nächste Teil der robots.txt verhindert, dass alle Suchmaschinen die Website und die robots.txt crawlen.
Das erklärt wahrscheinlich, warum die Website bei Google deindexiert wird. Aber es erklärt nicht, warum es immer noch von Bing indiziert wird.
Ich habe mich umgehört und Adam Humphreys, ein Webentwickler und SEO (LinkedIn-Profil), meinte, dass es sein könnte, dass Bingbot nicht auf Muellers Website war, weil es sich um eine weitgehend inaktive Website handelt.
Adam hat mir seine Gedanken mitgeteilt:
“User-Agent: *
Nicht zulassen: /topsy/
Nicht zulassen: /crets/
Nicht zulassen: /hidden/file.htmlIn diesen Beispielen würden die Ordner und die Datei in diesem Ordner nicht gefunden.
Er sagt, man solle die Robots-Datei verbieten, die Bing ignoriert, aber Google hört zu.
Bing würde falsch implementierte Roboter ignorieren, weil viele nicht wissen, wie es geht. „
Adam schlug auch vor, dass Bing die robots.txt-Datei möglicherweise überhaupt nicht berücksichtigt hat.
Er hat es mir so erklärt:
„Ja, oder es ignoriert eine Anweisung, eine Anweisungsdatei nicht zu lesen.
Falsch implementierte Roboteranweisungen bei Bing werden wahrscheinlich ignoriert. Das ist für sie die logischste Antwort. Es ist eine Wegbeschreibungsdatei.“
Die robots.txt-Datei wurde zuletzt zwischen Juli und November 2023 aktualisiert. Daher kann es sein, dass Bingbot die neueste robots.txt-Datei nicht gesehen hat. Das ist sinnvoll, da das IndexNow-Webcrawling-System von Microsoft effizientes Crawling priorisiert.
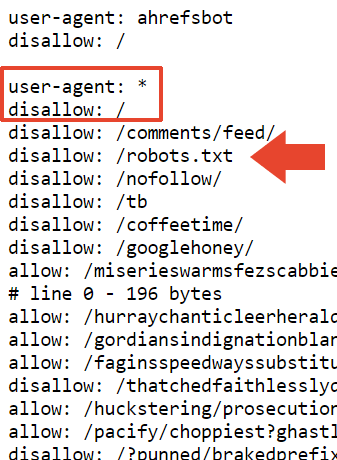
Eines der von Muellers robots.txt blockierten Verzeichnisse ist /nofollow/ (was ein seltsamer Name für einen Ordner ist).
Auf dieser Seite gibt es im Grunde nichts außer etwas Site-Navigation und dem Wort „Redirector“.
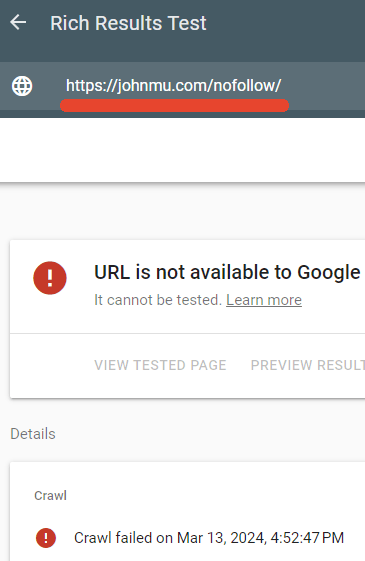
Ich habe getestet, ob die robots.txt-Datei diese Seite tatsächlich blockiert, und das war auch der Fall.
Der Rich-Suchergebnisse-Tester von Google konnte die Webseite /nofollow/ nicht crawlen.
John Muellers Erklärung
Mueller schien amüsiert darüber zu sein, dass seiner robots.txt so viel Aufmerksamkeit geschenkt wurde, und veröffentlichte auf LinkedIn eine Erklärung, was vor sich ging.
Er schrieb:
„Aber was ist mit der Akte los? Und warum wird Ihre Website deindexiert?
Jemand vermutete, dass es an den Links zu Google+ liegen könnte. Es ist möglich. Und zurück zur robots.txt … es ist in Ordnung – ich meine, es ist so, wie ich es möchte, und Crawler können damit umgehen. Oder sie sollten dazu in der Lage sein, wenn sie RFC9309 befolgen.“
Als nächstes sagte er, dass das Nofollow in der robots.txt lediglich dazu diente, zu verhindern, dass sie als HTML-Datei indiziert wird.
Er erklärte:
„“disallow: /robots.txt“ – führt dies dazu, dass sich Roboter im Kreis drehen? Deindexiert dies Ihre Website? NEIN.
Meine robots.txt-Datei enthält einfach eine Menge Inhalt und sie ist sauberer, wenn sie nicht mit ihrem Inhalt indiziert wird. Dadurch wird lediglich verhindert, dass die robots.txt-Datei zu Indexierungszwecken gecrawlt wird.
Ich könnte auch den HTTP-Header x-robots-tag mit noindex verwenden, aber so habe ich ihn auch in der robots.txt-Datei.“
Mueller sagte auch Folgendes zur Dateigröße:
„Die Größe ergibt sich aus Tests der verschiedenen robots.txt-Testtools, an denen mein Team und ich gearbeitet haben. Laut RFC sollte ein Crawler mindestens 500 Kibibyte analysieren (Bonus-Likes für die erste Person, die erklärt, was für ein Snack das ist). Irgendwo muss man aufhören, man könnte Seiten erstellen, die unendlich lang sind (und das habe ich, und viele Leute haben es getan, manche sogar mit Absicht). In der Praxis passiert es, dass das System, das die robots.txt-Datei prüft (der Parser), irgendwo einen Schnitt macht.“
Er sagte auch, dass er diesem Abschnitt ein Verbot hinzugefügt habe, in der Hoffnung, dass es als „pauschales Verbot“ aufgefasst werde, aber ich bin mir nicht sicher, von welchem Verbot er spricht. Seine robots.txt-Datei enthält genau 22.433 Disallows.
Er schrieb:
„Ich habe über diesem Abschnitt ein „disallow: /“ hinzugefügt, also hoffe ich, dass das als pauschales Verbot aufgefasst wird. Es ist möglich, dass der Parser an einer unangenehmen Stelle abbricht, etwa in einer Zeile, die „allow: /cheeseisbest“ enthält und direkt am „/“ stoppt, was den Parser in eine Sackgasse bringen würde (und, trivial!, die Allow-Regel). wird überschrieben, wenn Sie sowohl „allow: /“ als auch „disallow: /“ haben. Dies erscheint jedoch sehr unwahrscheinlich.“
Und da ist es. John Muellers seltsame robots.txt.
Robots.txt hier sichtbar:
https://johnmu.com/robots.txt