Tag: Robots.txt

Google hatte darüber diskutiert, Noindex in Robots.txt zuzulassen
John Mueller von Google antwortete auf eine Frage auf LinkedIn, um die Verwendung einer nicht unterstützten Noindex-Direktive in der robots.txt-Datei seiner eigenen persönlichen Website zu diskutieren. Er erläuterte die Vor- und Nachteile der Suchmaschinenunterstützung für die Richtlinie und gab Einblicke in die internen Diskussionen von Google über deren Unterstützung.
John Muellers Robots.txt
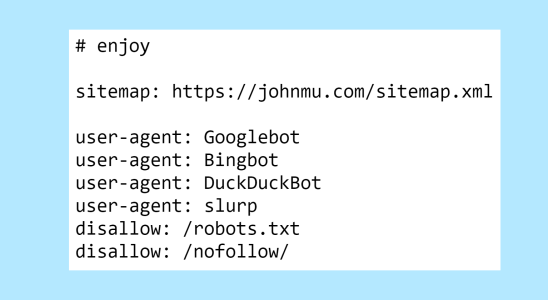
Muellers robots.txt sorgte in der letzten Woche für Gesprächsstoff, weil die seltsamen und nicht standardmäßigen Anweisungen, die er darin verwendete, allgemein seltsam waren.
Es war fast unvermeidlich, dass
Die Saga von John Muellers Freaky Robots.txt
Die robots.txt-Datei des persönlichen Blogs von John Mueller von Google geriet in den Mittelpunkt des Interesses, als jemand auf Reddit behauptete, Muellers Blog sei vom System „Hilfreiche Inhalte“ betroffen und daraufhin deindexiert worden. Die Wahrheit erwies sich als weniger dramatisch, war aber dennoch ein wenig seltsam.
SEO-Subreddit-Beitrag
Die Saga von John Muellers robots.txt begann, als ein Redditor veröffentlichte, dass die Website von John Mueller deindexiert wurde und dass sie mit dem Algorithmus von Google in Konflikt geraten sei. Aber so

8 häufige Probleme mit Robots.txt und wie man sie behebt
Robots.txt ist ein nützliches und leistungsstarkes Tool, mit dem Sie Suchmaschinen-Crawlern mitteilen können, wie sie Ihre Website crawlen sollen. Die Verwaltung dieser Datei ist eine Schlüsselkomponente guter technischer Suchmaschinenoptimierung.
Es ist nicht allmächtig – in den eigenen Worten von Google: „Es ist kein Mechanismus, um eine Webseite von Google fernzuhalten“ – aber es kann helfen, zu verhindern, dass Ihre Website oder Ihr Server durch Crawler-Anfragen überlastet wird.
Wenn Sie diesen Crawling-Block auf Ihrer Website haben, müssen Sie sicherstellen, dass er