
Anmerkung des Herausgebers: Das Jahr 2021 geht zu Ende und wir feiern dieses Jahr mit einem 12-Tage-Weihnachts-Countdown der beliebtesten und hilfreichsten Expertenartikel im Search Engine Journal.
Diese Sammlung wurde von unserem Redaktionsteam basierend auf der Leistung, dem Nutzen, der Qualität und dem Mehrwert jedes Artikels für Sie, unsere Leser, zusammengestellt.
Bis zum 24. Dezember veröffentlichen wir jeden Tag eine der besten Kolumnen des Jahres, beginnend bei Nr. 12 und Countdown bis Nr. 1. Unser Countdown beginnt heute mit unserer Nr. 3-Kolumne, die ursprünglich am 18. März veröffentlicht wurde , 2021.
Ruth Everetts Artikel über die Verwendung von Python-Bibliotheken zur Automatisierung und Durchführung von SEO-Aufgaben erleichtert die Arbeit eines Marketers erheblich. Es ist sehr einfach zu lesen und perfekt für Anfänger und noch erfahrenere SEO-Profis, die Python mehr verwenden möchten.
Tolle Arbeit dabei, Ruth, und wir wissen Ihre Beiträge zum Search Engine Journal sehr zu schätzen.
Genießen!
Python-Bibliotheken sind eine unterhaltsame und leicht zugängliche Möglichkeit, mit dem Erlernen und Verwenden von Python für SEO zu beginnen.
Anzeige
Weiter unten lesen
Eine Python-Bibliothek ist eine Sammlung nützlicher Funktionen und Code, mit denen Sie eine Reihe von Aufgaben erledigen können, ohne den Code von Grund auf neu schreiben zu müssen.
In Python stehen über 100.000 Bibliotheken zur Verfügung, die für Funktionen von der Datenanalyse bis zum Erstellen von Videospielen verwendet werden können.
In diesem Artikel finden Sie verschiedene Bibliotheken, die ich zum Abschließen von SEO-Projekten und -Aufgaben verwendet habe. Alle sind anfängerfreundlich und Sie finden zahlreiche Dokumentationen und Ressourcen, die Ihnen den Einstieg erleichtern.
Warum sind Python-Bibliotheken für SEO nützlich?
Jede Python-Bibliothek enthält Funktionen und Variablen aller Art (Arrays, Wörterbücher, Objekte usw.), mit denen verschiedene Aufgaben ausgeführt werden können.
Für SEO können sie beispielsweise verwendet werden, um bestimmte Dinge zu automatisieren, Ergebnisse vorherzusagen und intelligente Erkenntnisse zu liefern.
Es ist möglich, nur mit Vanilla-Python zu arbeiten, aber Bibliotheken können verwendet werden, um das Schreiben und Ausführen von Aufgaben viel einfacher und schneller zu machen.
Python-Bibliotheken für SEO-Aufgaben
Es gibt eine Reihe nützlicher Python-Bibliotheken für SEO-Aufgaben, einschließlich Datenanalyse, Web-Scraping und Visualisierung von Erkenntnissen.
Anzeige
Weiter unten lesen
Dies ist keine vollständige Liste, aber dies sind die Bibliotheken, die ich am häufigsten für SEO-Zwecke verwende.
Pandas
Pandas ist eine Python-Bibliothek, die zum Arbeiten mit Tabellendaten verwendet wird. Es ermöglicht eine Datenmanipulation auf hoher Ebene, wobei die Schlüsseldatenstruktur ein DataFrame ist.
DataFrames ähneln Excel-Kalkulationstabellen, sind jedoch nicht auf Zeilen- und Bytelimits beschränkt und auch viel schneller und effizienter.
Der beste Weg, um mit Pandas zu beginnen, besteht darin, eine einfache CSV-Datendatei (z. B. ein Crawling Ihrer Website) zu verwenden und diese in Python als DataFrame zu speichern.
Sobald Sie dies in Python gespeichert haben, können Sie eine Reihe verschiedener Analyseaufgaben ausführen, darunter das Aggregieren, Pivotieren und Bereinigen von Daten.
Wenn ich beispielsweise meine Website vollständig durchforstete und nur die Seiten extrahieren möchte, die indiziert werden können, verwende ich eine integrierte Pandas-Funktion, um nur diese URLs in meinen DataFrame aufzunehmen.
import pandas as pd
df = pd.read_csv('/Users/rutheverett/Documents/Folder/file_name.csv')
df.head
indexable = df[(df.indexable == True)]
indexable
Anfragen
Die nächste Bibliothek heißt Requests und wird verwendet, um HTTP-Anfragen in Python zu stellen.
Requests verwendet verschiedene Anfragemethoden wie GET und POST, um eine Anfrage zu stellen, wobei die Ergebnisse in Python gespeichert werden.
Ein Beispiel dafür in Aktion ist eine einfache GET-Anfrage einer URL, die den Statuscode einer Seite ausdruckt:
import requests
response = requests.get('https://www.deepcrawl.com') print(response)
Mit diesem Ergebnis können Sie dann eine Entscheidungsfunktion erstellen, bei der ein 200-Statuscode bedeutet, dass die Seite verfügbar ist, ein 404 bedeutet, dass die Seite nicht gefunden wurde.
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
Sie können auch verschiedene Anfragen wie Header verwenden, die nützliche Informationen über die Seite anzeigen, wie den Inhaltstyp oder wie lange es dauerte, die Antwort zwischenzuspeichern.
headers = response.headers print(headers) response.headers['Content-Type']
Es besteht auch die Möglichkeit, einen bestimmten Benutzeragenten wie den Googlebot zu simulieren, um die Antwort zu extrahieren, die dieser bestimmte Bot beim Crawlen der Seite sieht.
headers = 'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' ua_response = requests.get('https://www.deepcrawl.com/', headers=headers) print(ua_response)

Schöne Suppe
Beautiful Soup ist eine Bibliothek zum Extrahieren von Daten aus HTML- und XML-Dateien.
Anzeige
Weiter unten lesen
Wissenswertes: Die BeautifulSoup-Bibliothek wurde tatsächlich nach dem Gedicht aus Alice’s Adventures in Wonderland von Lewis Carroll benannt.
Als Bibliothek wird BeautifulSoup verwendet, um Webdateien zu verstehen, und wird am häufigsten für das Web-Scraping verwendet, da es ein HTML-Dokument in verschiedene Python-Objekte umwandeln kann.
Sie können beispielsweise eine URL verwenden und Beautiful Soup zusammen mit der Requests-Bibliothek verwenden, um den Titel der Seite zu extrahieren.
from bs4 import BeautifulSoup import requests url="https://www.deepcrawl.com" req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") title = soup.title print(title)

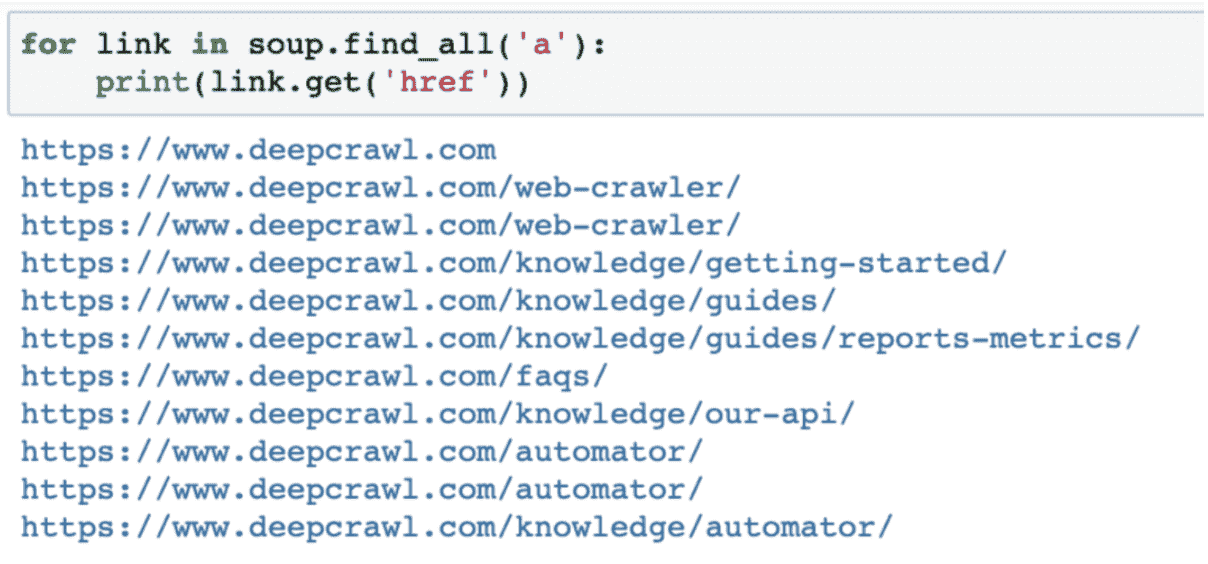
Außerdem können Sie mit der Methode find_all mit BeautifulSoup bestimmte Elemente aus einer Seite extrahieren, z. B. alle a href-Links auf der Seite:
Anzeige
Weiter unten lesen
url="https://www.deepcrawl.com/knowledge/technical-seo-library/"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
Zusammenfügen
Diese drei Bibliotheken können auch zusammen mit Requests verwendet werden, um die HTTP-Anfrage an die Seite zu senden, von der wir BeautifulSoup verwenden möchten, um Informationen zu extrahieren.
Wir können diese Rohdaten dann in einen Pandas DataFrame umwandeln, um weitere Analysen durchzuführen.
URL = 'https://www.deepcrawl.com/blog/'
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
links = soup.find_all('a')
df = pd.DataFrame('links':links)
df
Matplotlib und Seaborn
Matplotlib und Seaborn sind zwei Python-Bibliotheken, die zum Erstellen von Visualisierungen verwendet werden.
Mit Matplotlib können Sie eine Reihe verschiedener Datenvisualisierungen wie Balkendiagramme, Liniendiagramme, Histogramme und sogar Heatmaps erstellen.
Anzeige
Weiter unten lesen
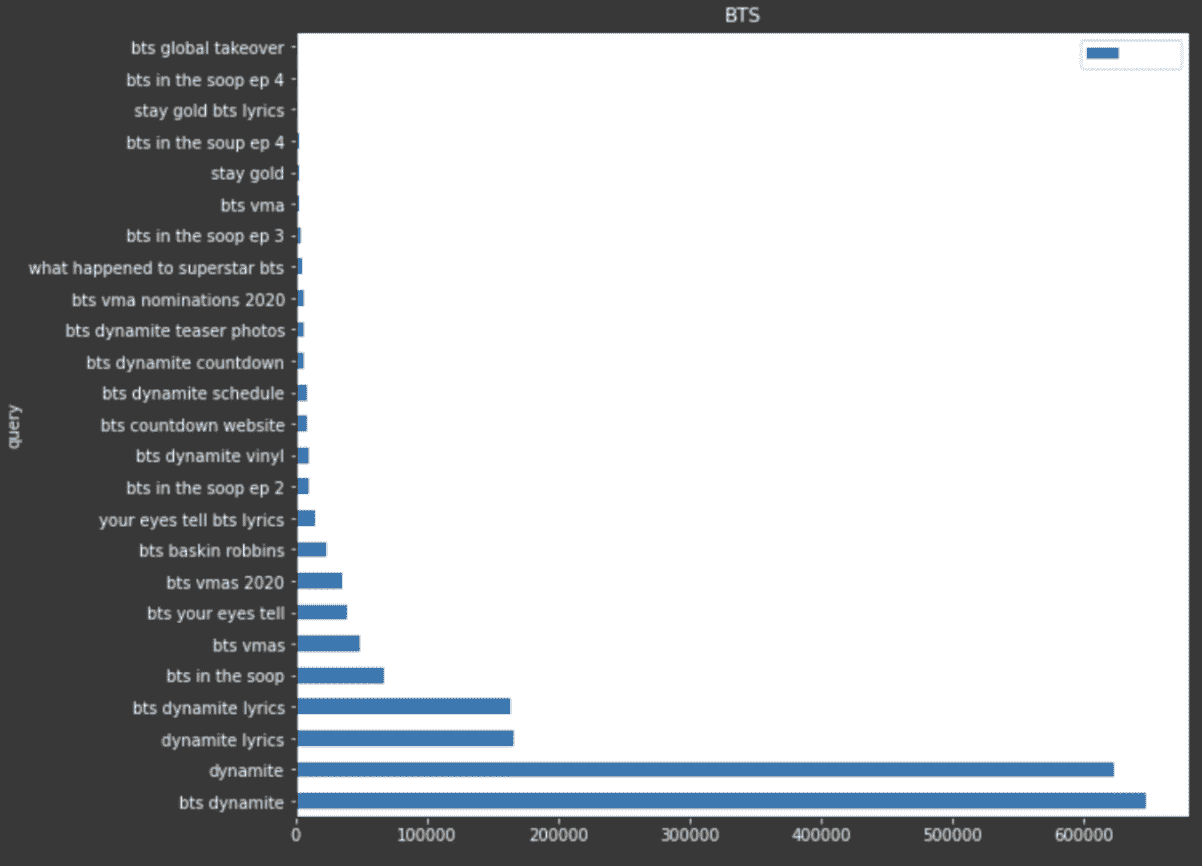
Wenn ich beispielsweise einige Google Trends-Daten verwenden wollte, um die Abfragen mit der größten Popularität über einen Zeitraum von 30 Tagen anzuzeigen, könnte ich ein Balkendiagramm in Matplotlib erstellen, um all dies zu visualisieren.
Seaborn, das auf Matplotlib basiert, bietet neben Linien- und Balkendiagrammen noch mehr Visualisierungsmuster wie Scatterplots, Boxplots und Violinplots.
Es unterscheidet sich geringfügig von Matplotlib, da es weniger Syntax verwendet und über integrierte Standardthemen verfügt.
Anzeige
Weiter unten lesen
Eine Möglichkeit, Seaborn zu verwenden, besteht darin, Liniendiagramme zu erstellen, um die Zugriffe auf Protokolldateien auf bestimmte Segmente einer Website im Laufe der Zeit zu visualisieren.
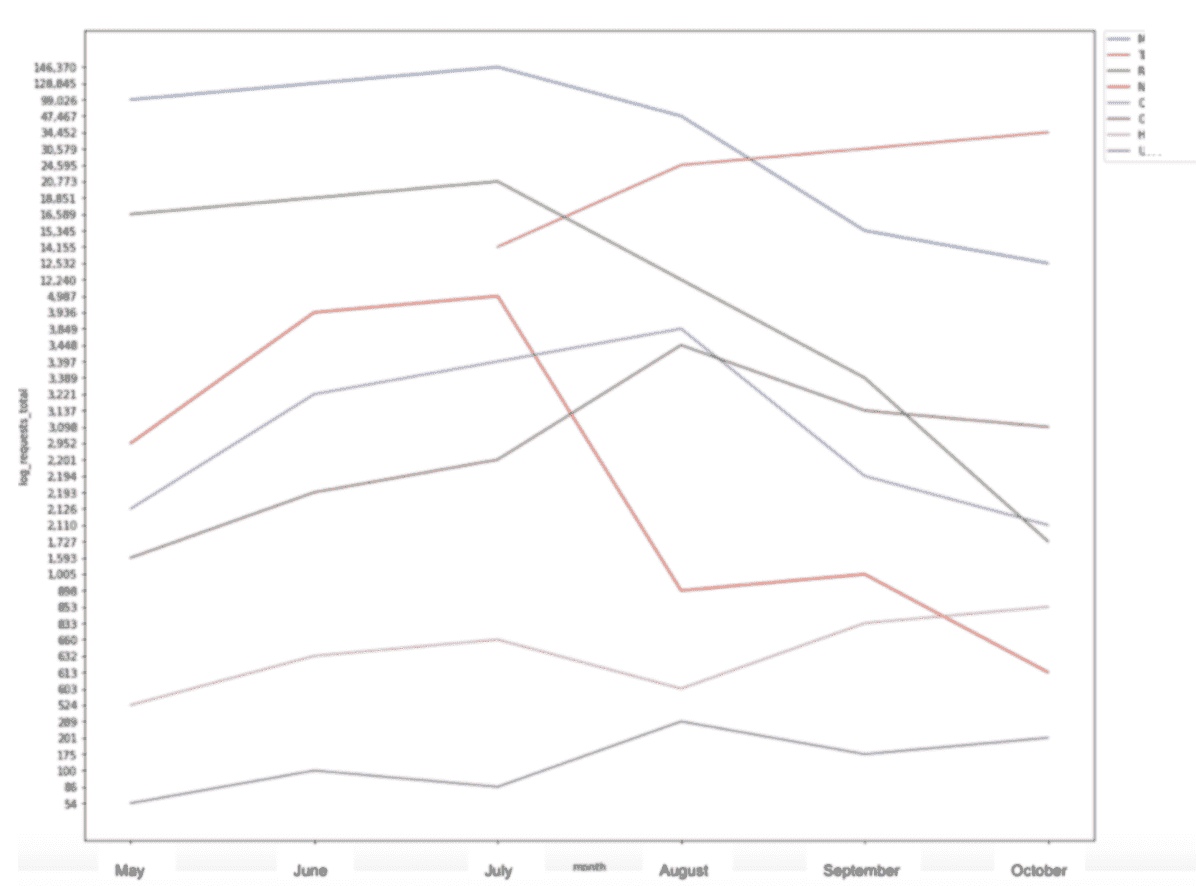
sns.lineplot(x = "month", y = "log_requests_total", hue="category", data=pivot_status) plt.show()
Dieses spezielle Beispiel nimmt Daten aus einer Pivot-Tabelle, die ich in Python mit der Pandas-Bibliothek erstellen konnte, und ist eine weitere Möglichkeit, wie diese Bibliotheken zusammenarbeiten, um ein leicht verständliches Bild aus den Daten zu erstellen.
Werbetools
Adverttools ist eine Bibliothek erstellt von Elias Dabbas die verwendet werden können, um die Daten, die wir als SEO-Experten und digitale Vermarkter haben, zu verwalten, zu verstehen und Entscheidungen zu treffen.
Anzeige
Weiter unten lesen
Sitemap-Analyse
Mit dieser Bibliothek können Sie eine Reihe verschiedener Aufgaben ausführen, z. B. das Herunterladen, Analysieren und Analysieren von XML-Sitemaps, um Muster zu extrahieren oder zu analysieren, wie oft Inhalt hinzugefügt oder geändert wird.
Robots.txt-Analyse
Eine weitere interessante Sache, die Sie mit dieser Bibliothek machen können, ist die Verwendung einer Funktion zum Extrahieren der robots.txt einer Website in einen DataFrame, um die festgelegten Regeln leicht zu verstehen und zu analysieren.
Sie können auch innerhalb der Bibliothek einen Test durchführen, um zu überprüfen, ob ein bestimmter User-Agent bestimmte URLs oder Ordnerpfade abrufen kann.
URL-Analyse
Mit Adverttools können Sie auch URLs analysieren und analysieren, um Informationen zu extrahieren und Analyse-, SERP- und Crawling-Daten für bestimmte URLs besser zu verstehen.
Sie können URLs auch mithilfe der Bibliothek aufteilen, um Dinge wie das verwendete HTTP-Schema, den Hauptpfad, zusätzliche Parameter und Abfragezeichenfolgen zu bestimmen.
Selen
Selenium ist eine Python-Bibliothek, die im Allgemeinen für Automatisierungszwecke verwendet wird. Der häufigste Anwendungsfall ist das Testen von Webanwendungen.
Anzeige
Weiter unten lesen
Ein beliebtes Beispiel für die Automatisierung eines Ablaufs durch Selenium ist ein Skript, das einen Browser öffnet und eine Reihe verschiedener Schritte in einer definierten Reihenfolge ausführt, beispielsweise das Ausfüllen von Formularen oder das Klicken auf bestimmte Schaltflächen.
Selenium verwendet das gleiche Prinzip wie in der Requests-Bibliothek, die wir zuvor behandelt haben.
Es sendet jedoch nicht nur die Anfrage und wartet auf die Antwort, sondern rendert auch die angeforderte Webseite.
Um mit Selenium zu beginnen, benötigen Sie einen WebDriver, um die Interaktionen mit dem Browser durchzuführen.
Jeder Browser hat seinen eigenen WebDriver; Chrome verfügt beispielsweise über ChromeDriver und Firefox über GeckoDriver.
Diese sind einfach herunterzuladen und mit Ihrem Python-Code einzurichten. Hier ist ein nützlicher Artikel, der den Einrichtungsprozess mit einem Beispielprojekt erklärt.
kratzig
Die letzte Bibliothek, die ich in diesem Artikel behandeln wollte, ist Scrapy.
Während wir das Requests-Modul verwenden können, um interne Daten von einer Webseite zu crawlen und zu extrahieren, müssen wir diese Daten jedoch auch mit BeautifulSoup kombinieren, um diese Daten weiterzugeben und nützliche Erkenntnisse zu gewinnen.
Anzeige
Weiter unten lesen
Mit Scrapy können Sie im Wesentlichen beides in einer Bibliothek tun.
Scrapy ist auch erheblich schneller und leistungsfähiger, führt Crawling-Anfragen aus, extrahiert und analysiert Daten in einer festgelegten Reihenfolge und ermöglicht es Ihnen, die Daten abzuschirmen.
In Scrapy können Sie eine Reihe von Anweisungen definieren, z. B. den Namen der Domain, die Sie crawlen möchten, die Start-URL und bestimmte Seitenordner, die der Spider durchsuchen darf oder nicht.
Mit Scrapy lassen sich alle Links einer bestimmten Seite extrahieren und beispielsweise in einer Ausgabedatei speichern.
class SuperSpider(CrawlSpider):
name="extractor"
allowed_domains = ['www.deepcrawl.com']
start_urls = ['https://www.deepcrawl.com/knowledge/technical-seo-library/']
base_url="https://www.deepcrawl.com"
def parse(self, response):
for link in response.xpath('//div/p/a'):
yield
"link": self.base_url + link.xpath('.//@href').get()
Sie können noch einen Schritt weiter gehen und den auf einer Webseite gefundenen Links folgen, um Informationen von allen Seiten zu extrahieren, auf die von der Start-URL aus verlinkt wird, wie eine kleine Nachbildung der Google-Suchergebnisse und dem Folgen von Links auf einer Seite.
from scrapy.spiders import CrawlSpider, Rule
class SuperSpider(CrawlSpider):
name="follower"
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Web_scraping']
base_url="https://en.wikipedia.org"
custom_settings =
'DEPTH_LIMIT': 1
def parse(self, response):
for next_page in response.xpath('.//div/p/a'):
yield response.follow(next_page, self.parse)
for quote in response.xpath('.//h1/text()'):
yield 'quote': quote.extract()
Erfahren Sie hier mehr über diese Projekte, neben anderen Beispielprojekten.
Abschließende Gedanken
Wie Hamlet Batista immer sagte: „Der beste Weg, um zu lernen, ist durch Handeln.“
Anzeige
Weiter unten lesen
Ich hoffe, dass die Entdeckung einiger der verfügbaren Bibliotheken Sie dazu inspiriert hat, mit dem Erlernen von Python zu beginnen oder Ihr Wissen zu vertiefen.
Python-Beiträge aus der SEO-Branche
Hamlet liebte es auch, Ressourcen und Projekte aus der Python-SEO-Community zu teilen. Um seine Leidenschaft für die Ermutigung anderer zu ehren, wollte ich einige der erstaunlichen Dinge teilen, die ich von der Community gesehen habe.
Als wunderbare Hommage an Hamlet und die SEO-Python-Community, die er mit aufgebaut hat, Charly Wargnier hat SEO Pythonistas gegründet, um Beiträge zu den erstaunlichen Python-Projekten zu sammeln, die die SEO-Community erstellt hat.
Hamlets unschätzbare Beiträge zur SEO-Community werden vorgestellt.
Moshe Ma-yafit ein super cooles Skript für die Logdatei-Analyse erstellt und in diesem Beitrag erklärt, wie das Skript funktioniert. Die Visualisierungen, die es anzeigen kann, umfassen Google Bot Hits by Device, Daily Hits by Response Code, Response Code % Total und mehr.
Koray Tuğberk GÜBÜR arbeitet derzeit an einem Sitemap-Health-Checker. Er veranstaltete auch ein RankSense-Webinar mit Elias Dabbas, in dem er ein Skript teilte, das SERPs aufzeichnet und Algorithmen analysiert.
Anzeige
Weiter unten lesen
Es zeichnet im Wesentlichen SERPs mit regelmäßigen Zeitunterschieden auf, und Sie können alle Zielseiten durchsuchen, Daten mischen und einige Korrelationen erstellen.
John McAlpin hat einen Artikel geschrieben, in dem beschrieben wird, wie Sie mit Python und Data Studio Ihre Konkurrenten ausspionieren können.
JC Chouinard hat eine vollständige Anleitung zur Verwendung der Reddit-API geschrieben. Damit können Sie Dinge wie das Extrahieren von Daten aus Reddit und das Posten in einem Subreddit durchführen.
Rob May arbeitet an einem neuen GSC-Analysetool und baut ein paar neue Domain-/Realsites in Wix auf, um sich mit seinem höherwertigen WordPress-Konkurrenten zu messen und gleichzeitig zu dokumentieren.
Masaki Okazawa hat auch ein Skript geteilt, das Google Search Console-Daten mit Python analysiert.
? Glücklich #RSTwittorial Donnerstag mit @saksters ?
Analysieren von Google Search Console-Daten mit #Python ??
Hier ist die Ausgabe ? pic.twitter.com/9l5Xc6UsmT
— RankSense (@RankSense) 25. Februar 2021
2021 SEJ-Weihnachts-Countdown:
Anzeige
Weiter unten lesen
Ausgewähltes Bild: jakkaje879/Shutterstock