
Google has officially presented version 1.0 of its new AI model “Gemini”. According to the release, it can “simultaneously understand and seamlessly combine” text, code, audio, images and video. Google’s new artificial intelligence will be designed in three sizes for different tasks and systems and, according to Google CEO Sundar Pichai, it comes “not a moment too soon”. The model will be “integrated into Google’s search engine, advertising products, Chrome browser and more around the world.”
Advertisement
Gemini for smartphones and businesses
The AI model, which is initially available in English – others are to follow – appears in three versions: “Gemini Nano” is intended to run as an efficient model locally and on mobile devices such as the Google Pixel 8 smartphone. According to Google, the more powerful “Gemini Pro” is now in use for Bard and will soon be available in other Google AI services. “Gemini Ultra” is the largest and most powerful model for highly complex tasks, but is also the most resource-intensive and slowest. “Ultra” is scheduled to be released next year.
Developers and enterprise customers will be able to access Gemini Pro via Google Generative AI Studio or Vertex AI on Google Cloud starting December 13th, reports The Verge.
Benchmarks and training
Because Gemini is “inherently multimodal and trained on different modalities from the start,” it is better than other models, Google claims in its statement. According to internal testing, Gemini Ultra outperforms other models in 30 of 32 academic benchmarks used in large language model research and development (LLM). According to the statement, the image benchmarks are more successful than previous models, without the support of OCR systems in which text is extracted from images for further processing.
In the Massive Multitask Language Understanding test (MMLU), which includes 57 tasks in mathematics, US history, computer science and law, Gemini Ultra achieved a score of 90 percent, outperforming human experts. In the MMMU benchmark, Google’s largest AI model also achieved a top value of 59.4 percent. The Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark (MMMU) is designed to evaluate multimodal models in large-scale multidisciplinary tasks that require college-level expertise and thoughtful thinking from the fields of art and design, business, science, health and medicine, Require humanities and social sciences as well as technology and engineering.
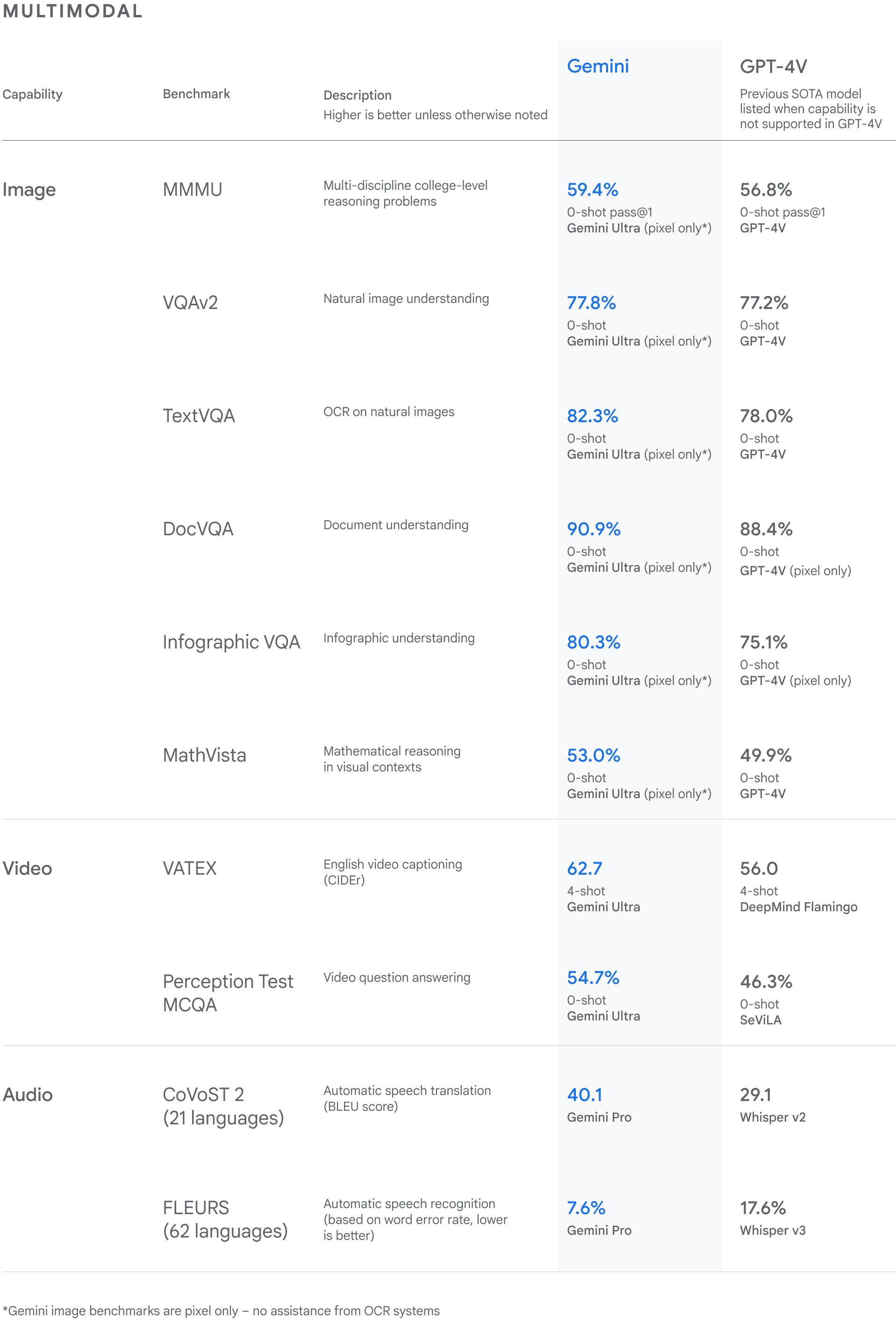
MMMU benchmark
(Image: Google)
Gemini was announced at Google I/O in May of this year, but was a bit quiet at the time. According to Pichai and Demis Hassabis, CEO of Google DeepMind, Gemini is a giant leap forward in an AI model that will ultimately impact virtually all of Google’s products. “One of the most important things at this moment,” says Pichai, “is that you can work on an underlying technology and improve it, and that will be immediately incorporated into all of our products.”
(bme)