News-Sitemaps verwenden unterschiedliche und einzigartige Sitemap-Protokolle, um mehr Informationen für die News-Suchmaschinen bereitzustellen.
Eine Nachrichten-Sitemap enthält die Nachrichten, die in den letzten 48 Stunden veröffentlicht wurden.
Nachrichten-Sitemap-Tags enthalten den Titel, die Sprache, den Namen, das Genre, das Veröffentlichungsdatum, Schlüsselwörter und sogar Börsenticker der Nachrichtenveröffentlichung.
Wie können Sie diese Sitemaps zu Ihrem Vorteil für die Inhaltsrecherche und Wettbewerbsanalyse nutzen?
In diesem Python-Tutorial lernen Sie einen 10-Schritte-Prozess zum Analysieren von News-Sitemaps und zum Visualisieren von darin entdeckten aktuellen Trends kennen.
Hinweise zur Haushaltsführung für den Einstieg
Dieses Tutorial wurde während der russischen Invasion in der Ukraine geschrieben.
Mithilfe von maschinellem Lernen können wir Nachrichtenquellen und Artikel sogar danach kennzeichnen, welche Nachrichtenquelle „objektiv“ und welche Nachrichtenquelle „sarkastisch“ ist.
Aber der Einfachheit halber konzentrieren wir uns auf Themen mit Frequenzanalyse.
Wir werden mehr als 10 globale Nachrichtenquellen in den USA und Großbritannien nutzen
Hinweis: Wir würden gerne russische Nachrichtenquellen einbeziehen, aber sie haben keine richtige News-Sitemap. Selbst wenn sie es getan hätten, blockieren sie die externen Anfragen.
Vergleich des Wortvorkommens von „Invasion“ und „Befreiung“ aus westlichen und östlichen Nachrichtenquellen zeigt den Nutzen von Textanalysemethoden mit Verteilungshäufigkeit.
Was Sie brauchen, um Nachrichteninhalte mit Python zu analysieren
Die zugehörigen Python-Bibliotheken zum Auditieren einer Nachrichten-Sitemap, um die Inhaltsstrategie der Nachrichtenquelle zu verstehen, sind unten aufgeführt:
- Werbung.
- Pandas.
- Plotly Express, Subplots und Graph-Objekte.
- Re (Regex).
- Schnur.
- NLTK (Korpus, Stoppwörter, Ngrams).
- Unicodedaten.
- Matplotlib.
- Grundlegendes Verständnis der Python-Syntax.
10 Schritte zur Analyse von News-Sitemaps mit Python
Alles eingerichtet? Lasst uns anfangen.
1. Nehmen Sie die News-URLs aus der News-Sitemap
Wir haben „The Guardian“, „New York Times“, „Washington Post“, „Daily Mail“, „Sky News“, „BBC“ und „CNN“ ausgewählt, um die News-URLs aus den News-Sitemaps zu untersuchen.
df_guardian = adv.sitemap_to_df("http://www.theguardian.com/sitemaps/news.xml")
df_nyt = adv.sitemap_to_df("https://www.nytimes.com/sitemaps/new/news.xml.gz")
df_wp = adv.sitemap_to_df("https://www.washingtonpost.com/arcio/news-sitemap/")
df_bbc = adv.sitemap_to_df("https://www.bbc.com/sitemaps/https-index-com-news.xml")
df_dailymail = adv.sitemap_to_df("https://www.dailymail.co.uk/google-news-sitemap.xml")
df_skynews = adv.sitemap_to_df("https://news.sky.com/sitemap-index.xml")
df_cnn = adv.sitemap_to_df("https://edition.cnn.com/sitemaps/cnn/news.xml")
2. Untersuchen Sie eine Beispiel-News-Sitemap mit Python
Ich habe BBC als Beispiel verwendet, um zu demonstrieren, was wir gerade aus diesen Nachrichten-Sitemaps extrahiert haben.
df_bbc
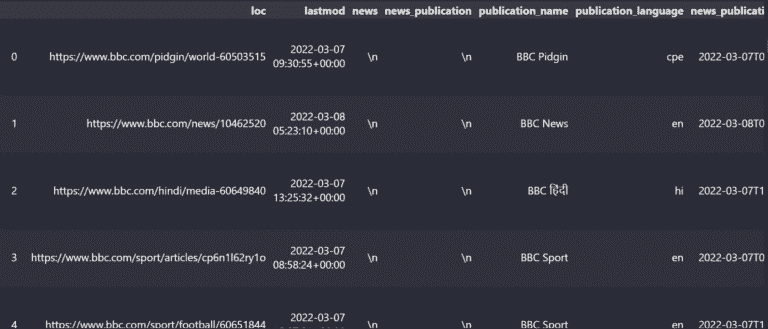
Die BBC-Sitemap enthält die folgenden Spalten.
df_bbc.columns
 News-Sitemap-Tags als Datenrahmenspalten
News-Sitemap-Tags als DatenrahmenspaltenDie allgemeinen Datenstrukturen dieser Spalten sind unten aufgeführt.
df_bbc.info()
 News Sitemap Spalten und Datentypen
News Sitemap Spalten und DatentypenDie BBC verwendet die Spalte „news_publication“ und andere nicht.
3. Finden Sie die am häufigsten verwendeten Wörter in URLs von Nachrichtenpublikationen
Um die am häufigsten verwendeten Wörter in den URLs der Nachrichtenseiten zu sehen, müssen wir die Methoden „str“, „explode“ und „split“ verwenden.
df_dailymail["loc"].str.split("/").str[5].str.split("-").explode().value_counts().to_frame()
loc |
|
|---|---|
article |
176 |
Russian |
50 |
Ukraine |
50 |
says |
38 |
reveals |
38 |
... |
... |
readers |
1 |
Red |
1 |
Cross |
1 |
provide |
1 |
weekend.html |
1 |
5445 rows × 1 column
Wir sehen, dass für die „Daily Mail“ „Russland und die Ukraine“ das Hauptthema sind.
4. Finden Sie die am häufigsten verwendete Sprache in Nachrichtenpublikationen
Die URL-Struktur oder der Abschnitt „Sprache“ der Nachrichtenveröffentlichung können verwendet werden, um die am häufigsten verwendeten Sprachen in Nachrichtenveröffentlichungen anzuzeigen.
In diesem Beispiel haben wir „BBC“ verwendet, um ihre Sprachpriorisierung anzuzeigen.
df_bbc["publication_language"].head(20).value_counts().to_frame()
| Veröffentlichungssprache | |
en |
698 |
fa |
52 |
sr |
52 |
ar |
47 |
mr |
43 |
hi |
43 |
gu |
41 |
ur |
35 |
pt |
33 |
te |
31 |
ta |
31 |
cy |
30 |
ha |
29 |
tr |
28 |
es |
25 |
sw |
22 |
cpe |
22 |
ne |
21 |
pa |
21 |
yo |
20 |
20 rows × 1 column
Um die russische Bevölkerung über Google News zu erreichen, sollte jede westliche Nachrichtenquelle die russische Sprache verwenden.
Einige internationale Nachrichteninstitute begannen, diese Perspektive darzustellen.
Wenn Sie ein Nachrichten-SEO sind, ist es hilfreich, russischsprachige Veröffentlichungen von Wettbewerbern zu beobachten, um die objektiven Nachrichten nach Russland zu verbreiten und in der Nachrichtenbranche zu konkurrieren.
5. Prüfen Sie die Nachrichtentitel auf die Häufigkeit von Wörtern
Wir haben BBC verwendet, um die „Nachrichtentitel“ zu sehen und welche Wörter häufiger vorkommen.
df_bbc["news_title"].str.split(" ").explode().value_counts().to_frame()
news_title |
|
|---|---|
to |
232 |
in |
181 |
- |
141 |
of |
140 |
for |
138 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11916 rows × 1 columns
Das Problem dabei ist, dass wir „jede Art von Wörtern in den Nachrichtentiteln“ haben, wie z. B. „kontextlose Stoppwörter“.
Wir müssen diese Arten von nicht kategorialen Begriffen bereinigen, um ihren Fokus besser zu verstehen.
from nltk.corpus import stopwords
stop = stopwords.words('english')
df_bbc_news_title_most_used_words = df_bbc["news_title"].str.split(" ").explode().value_counts().to_frame()
pat = r'\b(?:)\b'.format('|'.join(stop))
df_bbc_news_title_most_used_words.reset_index(drop=True, inplace=True)
df_bbc_news_title_most_used_words["without_stop_words"] = df_bbc_news_title_most_used_words["words"].str.replace(pat,"")
df_bbc_news_title_most_used_words.drop(df_bbc_news_title_most_used_words.loc[df_bbc_news_title_most_used_words["without_stop_words"]==""].index, inplace=True)
df_bbc_news_title_most_used_words
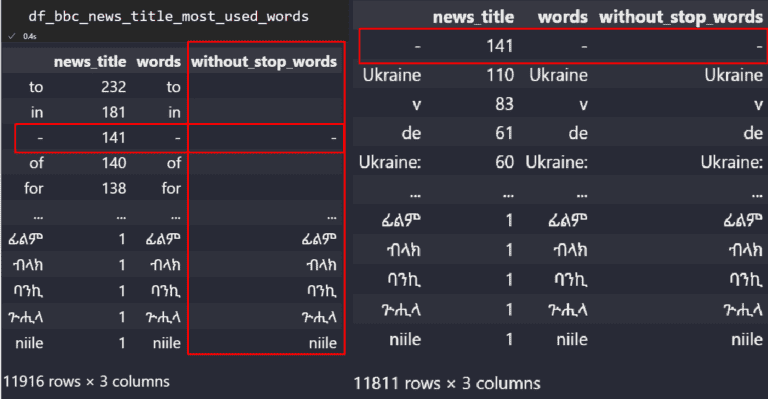 Die Spalte „without_stop_words“ enthält die bereinigten Textwerte.
Die Spalte „without_stop_words“ enthält die bereinigten Textwerte.Die meisten Stoppwörter haben wir mit Hilfe der „regex“- und „replace“-Methode von Pandas entfernt.
Das zweite Anliegen ist das Entfernen der „Interpunktionen“.
Dazu verwenden wir das „string“-Modul von Python.
import string
df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] = df_bbc_news_title_most_used_words['without_stop_words'].str.replace('[]'.format(string.punctuation), '')
df_bbc_news_title_most_used_words.drop(df_bbc_news_title_most_used_words.loc[df_bbc_news_title_most_used_words["without_stop_word_and_punctation"]==""].index, inplace=True)
df_bbc_news_title_most_used_words.drop(["without_stop_words", "words"], axis=1, inplace=True)
df_bbc_news_title_most_used_words
news_title |
without_stop_word_and_punctation |
|
|---|---|---|
Ukraine |
110 |
Ukraine |
v |
83 |
v |
de |
61 |
de |
Ukraine: |
60 |
Ukraine |
da |
51 |
da |
... |
... |
... |
ፊልም |
1 |
ፊልም |
ብላክ |
1 |
ብላክ |
ባንኪ |
1 |
ባንኪ |
ጕሒላ |
1 |
ጕሒላ |
niile |
1 |
niile |
11767 rows × 2 columns
Oder verwenden Sie „df_bbc_news_title_most_used_words[“news_title”].to_frame()“, um ein klareres Bild der Daten zu erhalten.
news_title |
|
|---|---|
Ukraine |
110 |
v |
83 |
de |
61 |
Ukraine: |
60 |
da |
51 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11767 rows × 1 columns
Wir sehen 11.767 eindeutige Wörter in den URLs der BBC, und die Ukraine ist mit 110 Vorkommen am beliebtesten.
Es gibt verschiedene ukrainebezogene Ausdrücke aus dem Datenrahmen, wie z. B. „Ukraine:“.
Das „NLTK Tokenize“ kann verwendet werden, um diese Arten von verschiedenen Variationen zu vereinen.
Im nächsten Abschnitt wird eine andere Methode verwendet, um sie zu vereinen.
Hinweis: Wenn Sie die Dinge einfacher machen möchten, verwenden Sie Advertools wie unten.
adv.word_frequency(df_bbc["news_title"],phrase_len=2, rm_words=adv.stopwords.keys())
Das Ergebnis ist unten.
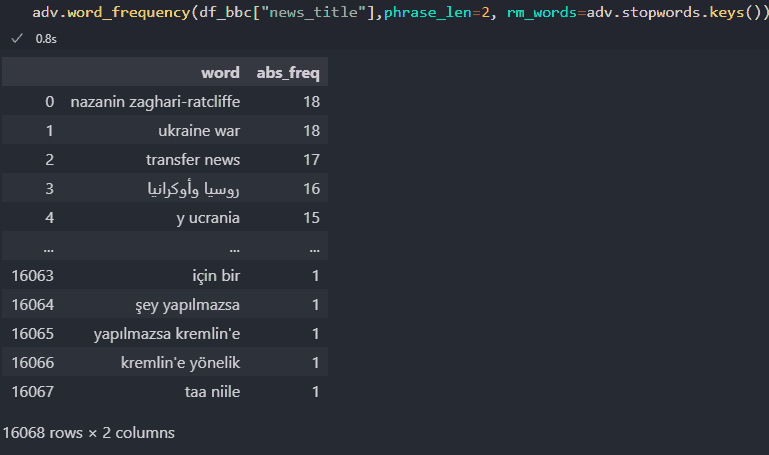 Textanalyse mit Advertools
Textanalyse mit Advertools„adv.word_frequency“ hat die Attribute „phrase_len“ und „rm_words“, um die Länge des Phrasenvorkommens zu bestimmen und die Stoppwörter zu entfernen.
Sie können mir sagen, warum ich es nicht gleich benutzt habe?
Ich wollte Ihnen ein lehrreiches Beispiel mit „Regex, NLTK und dem String“ zeigen, damit Sie verstehen, was hinter den Kulissen passiert.
6. Visualisieren Sie die am häufigsten verwendeten Wörter in Nachrichtentiteln
Um die am häufigsten verwendeten Wörter in den Nachrichtentiteln zu visualisieren, können Sie den folgenden Codeblock verwenden.
df_bbc_news_title_most_used_words["news_title"] = df_bbc_news_title_most_used_words["news_title"].astype(int) df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] = df_bbc_news_title_most_used_words["without_stop_word_and_punctation"].astype(str) df_bbc_news_title_most_used_words.index = df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] df_bbc_news_title_most_used_words["news_title"].head(20).plot(title="The Most Used Words in BBC News Titles")
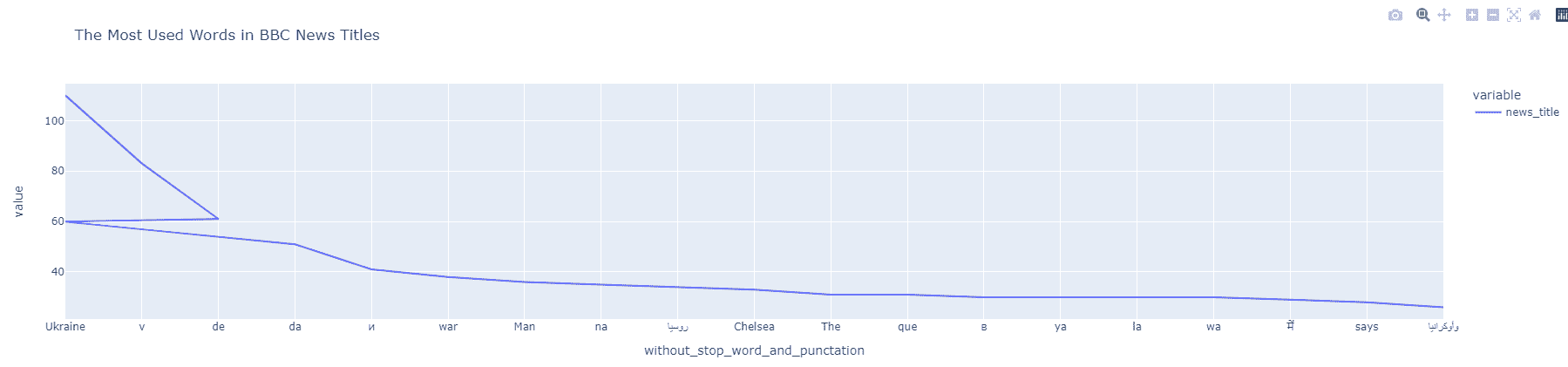 Neuigkeiten NGramms-Visualisierung
Neuigkeiten NGramms-VisualisierungSie erkennen, dass es eine „unterbrochene Linie“ gibt.
Erinnern Sie sich an „Ukraine“ und „Ukraine:“ im Datenrahmen?
Wenn wir die „Interpunktion“ entfernen, werden der zweite und der erste Wert gleich.
Deshalb sagt das Liniendiagramm, dass die Ukraine 60-mal und 110-mal separat erschienen ist.
Verwenden Sie den folgenden Codeblock, um eine solche Datendiskrepanz zu vermeiden.
df_bbc_news_title_most_used_words_1 = df_bbc_news_title_most_used_words.drop_duplicates().groupby('without_stop_word_and_punctation', sort=False, as_index=True).sum()
df_bbc_news_title_most_used_words_1
news_title |
|
|---|---|
without_stop_word_and_punctation |
|
Ukraine |
175 |
v |
83 |
de |
61 |
da |
51 |
и |
41 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11109 rows × 1 columns
Die duplizierten Zeilen werden gelöscht und ihre Werte werden summiert.
Jetzt visualisieren wir es noch einmal.
7. Extrahieren Sie die beliebtesten N-Gramme aus Nachrichtentiteln
Das Extrahieren von N-Grammen aus den Nachrichtentiteln oder das Normalisieren der URL-Wörter und das Bilden von N-Grammen zum Verständnis der Gesamtaktualität ist nützlich, um zu verstehen, welche Nachrichtenveröffentlichung sich welchem Thema nähert. Hier ist wie.
import nltk import unicodedata import re def text_clean(content):
lemmetizer = nltk.stem.WordNetLemmatizer()
stopwords = nltk.corpus.stopwords.words('english')
content = (unicodedata.normalize('NFKD', content)
.encode('ascii', 'ignore')
.decode('utf-8', 'ignore')
.lower())
words = re.sub(r'[^\w\s]', '', content).split()
return [lemmetizer.lemmatize(word) for word in words if word not in stopwords]
raw_words = text_clean(''.join(str(df_bbc['news_title'].tolist())))
raw_words[:10]
OUTPUT>>> ['oneminute', 'world', 'news', 'best', 'generation', 'make', 'agyarkos', 'dream', 'fight', 'card']
Die Ausgabe zeigt, dass wir alle Wörter in den Nachrichtentiteln „lemmatisiert“ und in eine Liste eingefügt haben.
Das Listenverständnis bietet eine schnelle Abkürzung zum einfachen Filtern jedes Stoppworts.
Die Verwendung von „nltk.corpus.stopwords.words(“english“)“ liefert alle Stoppwörter auf Englisch.
Sie können der Liste jedoch zusätzliche Stoppwörter hinzufügen, um den Ausschluss von Wörtern zu erweitern.
Die „Unicodedaten“ sollen die Zeichen kanonisieren.
Die Zeichen, die wir sehen, sind tatsächlich Unicode-Bytes wie „U+2160 ROMAN NUMERAL ONE“ und das römische Zeichen „U+0049 LATIN CAPITAL LETTER I“ sind eigentlich gleich.
Die „unicodedata.normalize“ unterscheidet die Zeichenunterschiede, damit der Lemmatizer die verschiedenen Wörter mit ähnlichen Zeichen voneinander unterscheiden kann.
pd.set_option("display.max_colwidth",90)
bbc_bigrams = (pd.Series(ngrams(words, n = 2)).value_counts())[:15].sort_values(ascending=False).to_frame()
bbc_trigrams = (pd.Series(ngrams(words, n = 3)).value_counts())[:15].sort_values(ascending=False).to_frame()
Unten sehen Sie die beliebtesten „N-Gramme“ von BBC News.
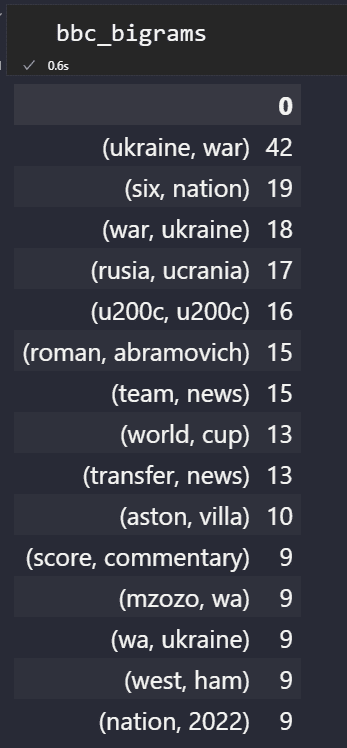 NGramms Dataframe von BBC
NGramms Dataframe von BBCVerwenden Sie den folgenden Codeblock, um die beliebtesten N-Gramme einer Nachrichtenquelle einfach zu visualisieren.
bbc_bigrams.plot.barh(color="red", width=.8,figsize=(10 , 7))
„Ukraine, Krieg“ ist die Trendmeldung.
Sie können die N-Gramme auch nach „Ukraine“ filtern und ein „Entitätsattribut“-Paar erstellen.
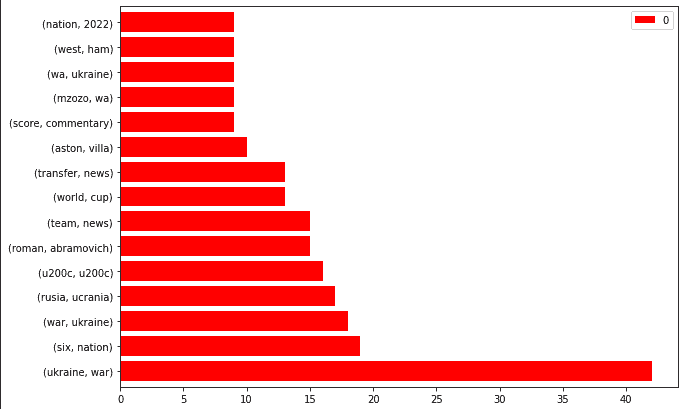 News Sitemap NGrams von BBC
News Sitemap NGrams von BBCDas Crawlen dieser URLs und das Erkennen der „personenartigen Entitäten“ kann Ihnen eine Vorstellung davon geben, wie die BBC mit berichtenswerten Situationen umgeht.
Aber es geht über „News-Sitemaps“ hinaus. So ist es für einen anderen Tag.
Um die beliebten N-Gramme aus den Sitemaps von Nachrichtenquellen zu visualisieren, können Sie wie unten beschrieben eine benutzerdefinierte Python-Funktion erstellen.
def ngram_visualize(dataframe:pd.DataFrame, color:str="blue") -> pd.DataFrame.plot:
dataframe.plot.barh(color=color, width=.8,figsize=(10 ,7))
ngram_visualize(ngram_extractor(df_dailymail))
Das Ergebnis ist unten.
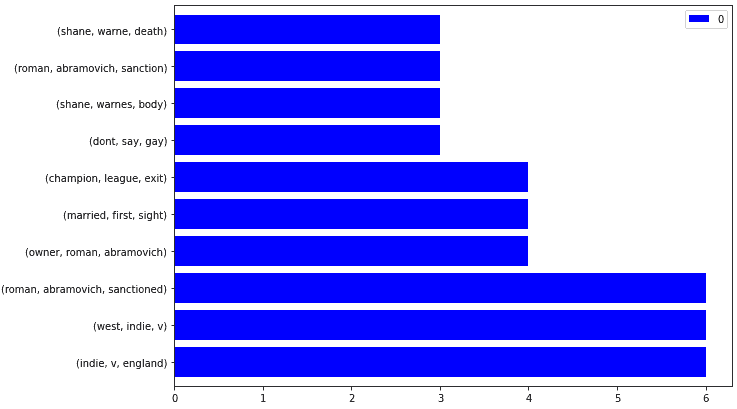 Nachrichten Sitemap Trigramm-Visualisierung
Nachrichten Sitemap Trigramm-VisualisierungUm es interaktiv zu machen, fügen Sie wie unten einen zusätzlichen Parameter hinzu.
def ngram_visualize(dataframe:pd.DataFrame, backend:str, color:str="blue", ) -> pd.DataFrame.plot:
if backend=="plotly":
pd.options.plotting.backend=backend
return dataframe.plot.bar()
else:
return dataframe.plot.barh(color=color, width=.8,figsize=(10 ,7))
ngram_visualize(ngram_extractor(df_dailymail), backend="plotly")
Als kurzes Beispiel siehe unten.
8. Erstellen Sie Ihre eigenen benutzerdefinierten Funktionen, um die Sitemaps der Nachrichtenquellen zu analysieren
Wenn Sie Nachrichten-Sitemaps wiederholt prüfen, wird ein kleines Python-Paket benötigt.
Unten finden Sie vier verschiedene schnelle Python-Funktionsketten, die jede vorherige Funktion als Callback verwenden.
Verwenden Sie die folgende Funktion, um ein Textinhaltselement zu bereinigen.
def text_clean(content):
lemmetizer = nltk.stem.WordNetLemmatizer()
stopwords = nltk.corpus.stopwords.words('english')
content = (unicodedata.normalize('NFKD', content)
.encode('ascii', 'ignore')
.decode('utf-8', 'ignore')
.lower())
words = re.sub(r'[^\w\s]', '', content).split()
return [lemmetizer.lemmatize(word) for word in words if word not in stopwords]
Verwenden Sie die folgende Funktion, um die N-Gramme aus den Nachrichtentiteln der Sitemap einer bestimmten Nachrichtenwebsite zu extrahieren.
def ngram_extractor(dataframe:pd.DataFrame|pd.Series):
if "news_title" in dataframe.columns:
return dataframe_ngram_extractor(dataframe, ngram=3, first=10)
Verwenden Sie die folgende Funktion, um die extrahierten N-Gramme in einen Datenrahmen umzuwandeln.
def dataframe_ngram_extractor(dataframe:pd.DataFrame|pd.Series, ngram:int, first:int):
raw_words = text_clean(''.join(str(dataframe['news_title'].tolist())))
return (pd.Series(ngrams(raw_words, n = ngram)).value_counts())[:first].sort_values(ascending=False).to_frame()
Verwenden Sie die nachstehende Funktion, um die Sitemaps mehrerer Nachrichten-Websites zu extrahieren.
def ngram_df_constructor(df_1:pd.DataFrame, df_2:pd.DataFrame):
df_1_bigrams = dataframe_ngram_extractor(df_1, ngram=2, first=500)
df_1_trigrams = dataframe_ngram_extractor(df_1, ngram=3, first=500)
df_2_bigrams = dataframe_ngram_extractor(df_2, ngram=2, first=500)
df_2_trigrams = dataframe_ngram_extractor(df_2, ngram=3, first=500)
ngrams_df =
"df_1_bigrams":df_1_bigrams.index,
"df_1_trigrams": df_1_trigrams.index,
"df_2_bigrams":df_2_bigrams.index,
"df_2_trigrams": df_2_trigrams.index,
dict_df = (pd.DataFrame( key:pd.Series(value) for key, value in ngrams_df.items() ).reset_index(drop=True)
.rename(columns="df_1_bigrams":adv.url_to_df(df_1["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_bigrams",
"df_1_trigrams":adv.url_to_df(df_1["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_trigrams",
"df_2_bigrams": adv.url_to_df(df_2["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_bigrams",
"df_2_trigrams": adv.url_to_df(df_2["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_trigrams"))
return dict_df
Unten sehen Sie einen beispielhaften Anwendungsfall.
ngram_df_constructor(df_bbc, df_guardian)
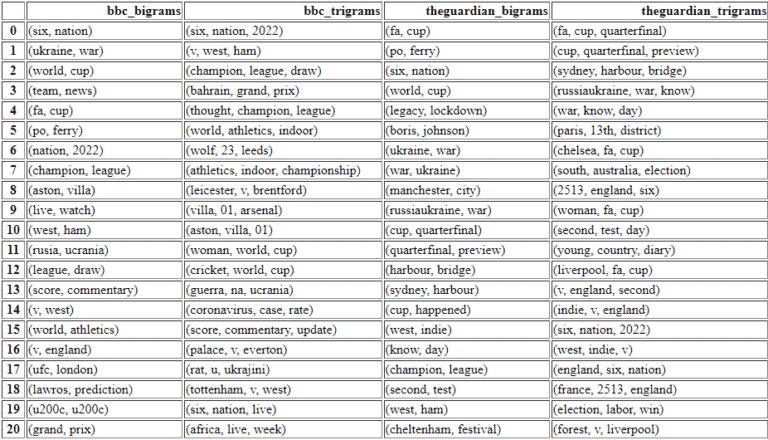 Beliebter Ngram-Vergleich, um den Fokus der Nachrichten-Websites zu sehen.
Beliebter Ngram-Vergleich, um den Fokus der Nachrichten-Websites zu sehen.Nur mit diesen vier verschachtelten benutzerdefinierten Python-Funktionen können Sie die folgenden Dinge tun.
- Sie können diese N-Gramme leicht visualisieren und die Nachrichten-Website zählt, um sie zu überprüfen.
- Sie können den Fokus der News-Websites für das gleiche Thema oder unterschiedliche Themen sehen.
- Sie können ihre Formulierungen oder den Wortschatz für dieselben Themen vergleichen.
- Sie können vergleichend sehen, wie viele verschiedene Unterthemen aus denselben Themen oder Entitäten bearbeitet werden.
Ich habe die Zahlen für die Frequenzen der N-Gramme nicht angegeben.
Aber die erstplatzierten sind die beliebtesten aus dieser bestimmten Nachrichtenquelle.
Um die nächsten 500 Zeilen zu untersuchen, klicken Sie hier.
9. Extrahieren Sie die am häufigsten verwendeten News-Keywords aus News-Sitemaps
Wenn es um Nachrichten-Keywords geht, sind sie überraschenderweise immer noch bei Google aktiv.
Beispielsweise halten Microsoft Bing und Google „Meta-Keywords“ im Gegensatz zu Yandex nicht mehr für ein nützliches Signal.
Nachrichten-Keywords aus den News-Sitemaps werden jedoch weiterhin verwendet.
Von all diesen Nachrichtenquellen verwendet nur The Guardian die Schlüsselwörter Nachrichten.
Und es ist hilfreich zu verstehen, wie sie Nachrichtenschlüsselwörter verwenden, um Relevanz bereitzustellen.
df_guardian["news_keywords"].str.split().explode().value_counts().to_frame().rename(columns="news_keywords":"news_keyword_occurence")
Sie können die am häufigsten verwendeten Wörter in den Nachrichten-Schlüsselwörtern für The Guardian sehen.
news_keyword_occurence |
|
|---|---|
news, |
250 |
World |
142 |
and |
142 |
Ukraine, |
127 |
UK |
116 |
... |
... |
Cumberbatch, |
1 |
Dune |
1 |
Saracens |
1 |
Pearson, |
1 |
Thailand |
1 |
1409 rows × 1 column
Die Visualisierung ist unten.
(df_guardian["news_keywords"].str.split().explode().value_counts() .to_frame().rename(columns="news_keywords":"news_keyword_occurence") .head(25).plot.barh(figsize=(10,8), title="The Guardian Most Used Words in News Keywords", xlabel="News Keywords", legend=False, ylabel="Count of News Keyword"))
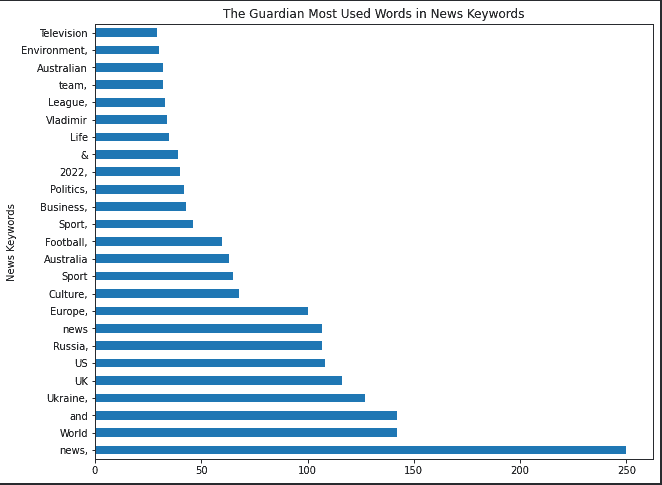 Die beliebtesten Wörter in Nachrichten-Keywords
Die beliebtesten Wörter in Nachrichten-KeywordsDas „,“ am Ende der News-Keywords gibt an, ob es sich um einen separaten Wert oder um einen Teil eines anderen handelt.
Ich schlage vor, dass Sie die „Satzzeichen“ oder „Stoppwörter“ nicht aus Nachrichten-Keywords entfernen, damit Sie den Verwendungsstil von Nachrichten-Keywords besser sehen können.
Für eine andere Analyse können Sie „,“ als Trennzeichen verwenden.
df_guardian["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns="news_keywords":"news_keyword_occurence")
Die Ergebnisdifferenz ist unten.
news_keyword_occurence |
|
|---|---|
World news |
134 |
Europe |
116 |
UK news |
111 |
Sport |
109 |
Russia |
90 |
... |
... |
Women's shoes |
1 |
Men's shoes |
1 |
Body image |
1 |
Kae Tempest |
1 |
Thailand |
1 |
1080 rows × 1 column
Konzentrieren Sie sich auf das „split(“,“).“
(df_guardian["news_keywords"].str.split(",").explode().value_counts()
.to_frame().rename(columns="news_keywords":"news_keyword_occurence")
.head(25).plot.barh(figsize=(10,8),
title="The Guardian Most Used Words in News Keywords", xlabel="News Keywords",
legend=False, ylabel="Count of News Keyword"))
Sie können den Ergebnisunterschied für die Visualisierung unten sehen.
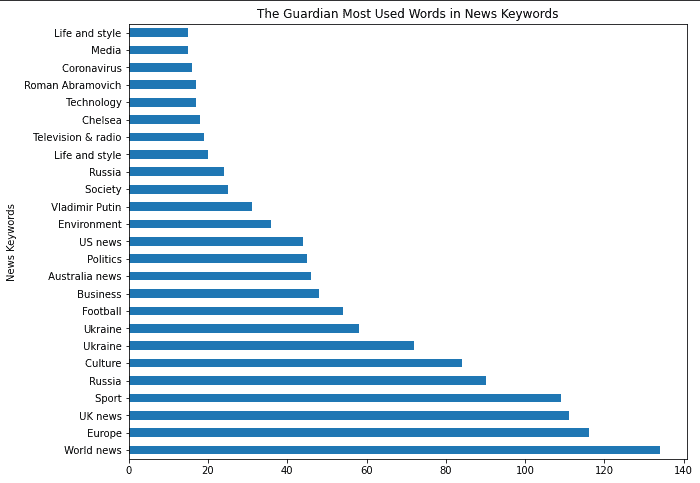 Die beliebtesten Keywords aus News-Sitemaps
Die beliebtesten Keywords aus News-SitemapsVon „Chelsea“ bis „Vladamir Putin“ oder „Ukrainekrieg“ und „Roman Abramowitsch“ stimmen die meisten dieser Phrasen mit den frühen Tagen der russischen Invasion in der Ukraine überein.
Verwenden Sie den Code-Block unten, um die News-Keywords von zwei verschiedenen News-Website-Sitemaps interaktiv zu visualisieren.
df_1 = df_guardian["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns="news_keywords":"news_keyword_occurence")
df_2 = df_nyt["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns="news_keywords":"news_keyword_occurence")
fig = make_subplots(rows = 1, cols = 2)
fig.add_trace(
go.Bar(y = df_1["news_keyword_occurence"][:6].index, x = df_1["news_keyword_occurence"], orientation="h", name="The Guardian News Keywords"), row=1, col=2
)
fig.add_trace(
go.Bar(y = df_2["news_keyword_occurence"][:6].index, x = df_2["news_keyword_occurence"], orientation="h", name="New York Times News Keywords"), row=1, col=1
)
fig.update_layout(height = 800, width = 1200, title_text="Side by Side Popular News Keywords")
fig.show()
fig.write_html("news_keywords.html")
Sie können das Ergebnis unten sehen.
Um mit dem Live-Chart zu interagieren, klicken Sie hier.
Im nächsten Abschnitt finden Sie zwei verschiedene Subplot-Beispiele, um die N-Gramme der Nachrichten-Websites zu vergleichen.
10. Erstellen Sie Subplots zum Vergleichen von Nachrichtenquellen
Verwenden Sie den Codeblock unten, um die beliebtesten N-Gramme der Nachrichtenquellen aus den Nachrichtentiteln in eine Nebenhandlung einzufügen.
import matplotlib.pyplot as plt
import pandas as pd
df1 = ngram_extractor(df_bbc)
df2 = ngram_extractor(df_skynews)
df3 = ngram_extractor(df_dailymail)
df4 = ngram_extractor(df_guardian)
df5 = ngram_extractor(df_nyt)
df6 = ngram_extractor(df_cnn)
nrow=3
ncol=2
df_list = [df1 ,df2, df3, df4, df5, df6] #df6
titles = ["BBC News Trigrams", "Skynews Trigrams", "Dailymail Trigrams", "The Guardian Trigrams", "New York Times Trigrams", "CNN News Ngrams"]
fig, axes = plt.subplots(nrow, ncol, figsize=(25,32))
count=0
i = 0
for r in range(nrow):
for c in range(ncol):
(df_list[count].plot.barh(ax = axes[r,c],
figsize = (40, 28),
title = titles[i],
fontsize = 10,
legend = False,
xlabel = "Trigrams",
ylabel = "Count"))
count+=1
i += 1
Sie können das Ergebnis unten sehen.
 Die beliebtesten NGrams aus Nachrichtenquellen
Die beliebtesten NGrams aus NachrichtenquellenDie obige Beispieldatenvisualisierung ist vollständig statisch und bietet keine Interaktivität.
Kürzlich hat Elias Dabbas, der Schöpfer von Advertools, ein neues Skript freigegeben, um die Anzahl der Artikel, N-Gramme und deren Anzahl aus den Nachrichtenquellen zu entnehmen.
Hier finden Sie ein besseres, detaillierteres und interaktives Daten-Dashboard.
Das obige Beispiel stammt von Elias Dabbas und er demonstriert, wie man die Gesamtzahl der Artikel, die häufigsten Wörter und N-Gramme auf interaktive Weise von Nachrichten-Websites erhält.
Abschließende Gedanken zur News-Sitemap-Analyse mit Python
Dieses Tutorial wurde entwickelt, um eine lehrreiche Python-Codierungssitzung bereitzustellen, um die Schlüsselwörter, N-Gramme, Phrasenmuster, Sprachen und andere Arten von SEO-bezogenen Informationen von Nachrichten-Websites zu entnehmen.
Nachrichten-SEO stützt sich stark auf schnelle Reflexe und die ständige Erstellung von Artikeln.
Das Verfolgen der Blickwinkel und Methoden Ihrer Konkurrenten zur Behandlung eines Themas zeigt, wie die Konkurrenten schnelle Reflexe für die Suchtrends haben.
Es wäre besser, ein Google Trends Dashboard und einen News Source Ngram Tracker für eine vergleichende und ergänzende Nachrichten-SEO-Analyse zu erstellen.
In diesem Artikel habe ich von Zeit zu Zeit benutzerdefinierte Funktionen oder erweiterte for-Schleifen eingefügt, und manchmal habe ich die Dinge einfach gehalten.
Anfänger bis hin zu fortgeschrittenen Python-Praktizierenden können davon profitieren, um ihre Tracking-, Berichterstellungs- und Analysemethoden für Nachrichten-SEO und darüber hinaus zu verbessern.
Mehr Ressourcen:
Beitragsbild: BestForBest/Shutterstock