Tag: Python

Massenladen von Leistungstests mit PageSpeed Insights API und Python
Google bietet die PageSpeed Insights API an, um SEO-Profis und Entwicklern zu helfen, indem sie Daten aus der realen Welt mit Simulationsdaten mischen und Zeitdaten zur Ladeleistung in Bezug auf Webseiten bereitstellen.
Der Unterschied zwischen Google PageSpeed Insights (PSI) und Lighthouse besteht darin, dass PSI sowohl reale als auch Labordaten umfasst, während Lighthouse eine Seitenladesimulation durchführt, indem es die Verbindung und den Benutzeragenten des Geräts modifiziert.
Ein weiterer Unterschied besteht darin, dass PSI keine Informationen in Bezug auf Webzugänglichkeit, SEO

Eine Schlange fangen: Die größte in den Everglades gefundene Python signalisiert eine Bedrohung
Der Staat versucht, die Erkennung von Pythons in freier Wildbahn zu verbessern, da sie geschickt darin sind, sich in abgelegenen Gebieten zu tarnen und anzusiedeln, sagte Frau Spencer.
„Wir müssen mehrere Methoden ausprobieren, mehrere Wege, um zu versuchen, diese Tiere zu kontrollieren“, sagte sie.
Burma-Pythons wurden in den 1980er Jahren durch den Handel mit exotischen Haustieren in die Everglades eingeführt, aber ihr Verkauf wurde 2012 verboten, sagte Stephen Leatherman, Professor für Erde und Umwelt an der Florida International University in

Konkurrenten-Backlink-Analyse mit Python [Complete Script]
In meinem letzten Artikel haben wir unsere Backlinks mit Daten von Ahrefs analysiert.
Dieses Mal beziehen wir die Backlinks der Konkurrenten in unsere Analyse ein und verwenden zum Vergleich dieselbe Ahrefs-Datenquelle.
Wie beim letzten Mal haben wir den Wert der Backlinks einer Website für SEO als ein Produkt aus Qualität und Quantität definiert.
Qualität ist die Domain-Autorität (oder die entsprechende Domain-Bewertung von Ahrefs) und Quantität ist die Anzahl der verweisenden Domains.
Auch hier werden wir die Verbindungsqualität mit den verfügbaren
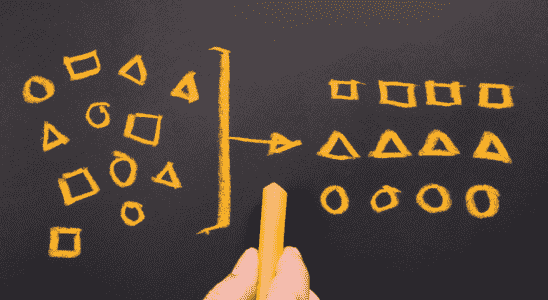
How To Automate Ecommerce Category Page Creation With Python
Clustering product inventory and automatically aligning SKUs to search demand is a great way to find opportunities to create new ecommerce categories.
Niche category pages are a proven way for ecommerce sites to align with organic search demand while simultaneously assisting users in purchasing.
If a site stocks a range of products and there is search demand, creating a dedicated landing page is an easy way to align with the demand.
But how can SEO professionals find this opportunity?
Sure,

Using Python + Streamlit To Find Striking Distance Keyword Opportunities
Python is an excellent tool to automate repetitive tasks as well as gain additional insights into data.
In this article, you’ll learn how to build a tool to check which keywords are close to ranking in positions one to three and advises whether there is an opportunity to naturally work those keywords into the page.
It’s perfect for Python beginners and pros alike and is a great introduction to using Python for SEO.
If you’d just like to get stuck

Visualisierung heißer Themen mit Python zur Analyse von News-Sitemaps
News-Sitemaps verwenden unterschiedliche und einzigartige Sitemap-Protokolle, um mehr Informationen für die News-Suchmaschinen bereitzustellen.
Eine Nachrichten-Sitemap enthält die Nachrichten, die in den letzten 48 Stunden veröffentlicht wurden.
Nachrichten-Sitemap-Tags enthalten den Titel, die Sprache, den Namen, das Genre, das Veröffentlichungsdatum, Schlüsselwörter und sogar Börsenticker der Nachrichtenveröffentlichung.
Wie können Sie diese Sitemaps zu Ihrem Vorteil für die Inhaltsrecherche und Wettbewerbsanalyse nutzen?
In diesem Python-Tutorial lernen Sie einen 10-Schritte-Prozess zum Analysieren von News-Sitemaps und zum Visualisieren von darin entdeckten aktuellen Trends kennen.

Wie man Backlink-Analysen mit Python visualisiert und anpasst
Wahrscheinlich haben Sie eines der bekannteren Tools wie Ahrefs oder Semrush verwendet, um die Backlinks Ihrer Website zu analysieren.
Diese Tools durchforsten das Web, um eine Liste von Websites zu erhalten, die auf Ihre Website verlinken, mit einer Domainbewertung und anderen Daten, die die Qualität Ihrer Backlinks beschreiben.
Es ist kein Geheimnis, dass Backlinks eine große Rolle im Algorithmus von Google spielen, daher ist es sinnvoll, zumindest die eigene Website zu verstehen, bevor man sie mit der Konkurrenz vergleicht.
Während
How To Do A Sitemap Audit For Better Indexing & Crawling Via Python
Sitemap auditing involves syntax, crawlability, and indexation checks for the URLs and tags in your sitemap files.
A sitemap file contains the URLs to index with further information regarding the last modification date, priority of the URL, images, videos on the URL, and other language alternates of the URL, along with the change frequency.
Sitemap index files can involve millions of URLs, even if a single sitemap can only involve 50,000 URLs at the top.
Auditing these URLs for better

Schlangenhorror: Einheimische haben Angst um Kinder und Haustiere, als monströse Python im Park frei herumläuft | Vereinigtes Königreich | Nachrichten
Die Anwohner waren besorgt um ihre Sicherheit, nachdem ein Mitglied der Öffentlichkeit die Tierschutzbeauftragten alarmiert hatte.
Die Schlange wurde am Dienstag gegen 7.30 Uhr in der Nähe des Shard End Lake gesichtet, was die Einheimischen besorgt um ihre Haustiere und Kinder machte.
Als die Inspektoren ankamen, konnten sie die Python, die bis zu 5 Fuß lang werden kann, nicht finden.
Eine Person schrieb in den sozialen Medien: „Ich nehme meine beiden Kinder und meinen Hund mit nach oben, ich werde

So erstellen Sie ein Empfehlungssystem mit TF-IDF und NMF (Python)
Themencluster und Empfehlungssysteme können SEO-Experten dabei helfen, eine skalierbare interne Verlinkungsarchitektur aufzubauen.
Und wie wir wissen, kann die interne Verlinkung sowohl die Benutzererfahrung als auch das Suchranking beeinflussen. Es ist ein Bereich, den wir richtig machen wollen.
In diesem Artikel verwenden wir Wikipedia-Daten, um Themencluster und Empfehlungssysteme mit Python und dem Datenanalysetool Pandas zu erstellen.
Um dies zu erreichen, verwenden wir die Scikit-learn-Bibliothek, eine kostenlose Software-Bibliothek für maschinelles Lernen für Python, mit zwei Hauptalgorithmen:
- TF-IDF: Termhäufigkeit-inverse Dokumenthäufigkeit.
- NMF